
分布式系统
分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统。
写在前面
本文是个人初步阅读知识摘抄和补充《分布式系统常用技术及案例分析》-柳伟卫,不用作任何商业用途,仅个人学习。 本文部分安装知识点为摘抄,仅提供参考文章。待自己需要搭建时,会记录相关的流程至其他文章中。 部分知识点会在后续学习中,深入了解,因此会仅学习理论知识点,部署使用知识。 部分知识暂时未学习归纳。
本书部分网页链接引用需要使用 vpn 后才能访问。
分布式系统
什么是分布式系统
《分布式系统原理与范型》一书中定义:
分布式系统是若干独立计算机的集合,这些计算机对于用户来说就像单个相关系统。
集中式系统 VS 分布式系统
- 集中式系统是把所有的功能都集成到主服务器上,这样对服务器要求很高,性能也不好,优点是便于维护,操作简单。
- 分布式系统是把各地不同地理位置的计算机集中起来形成一个系统。
分布式系统所面临的挑战
SLA(Service-Level Agreement, 服务水平协议)是衡量停机和/或性能下降的标准。
- 异构性: 由于基于不同的网络、操作系统、计算机硬件和编程语言来构造,必须考虑一种通用的网络通信协议来屏蔽异构系统间的差异。 (一般交由中间件来处理这些差异)
- 一致性: 数据被分散或者复制到不同机器上,如何保证个台主机之间的数据一致性将成为一个难点
- 故障的独立性: 任何计算机都有可能故障,且各种故障不尽相同。出现故障的时机也是相互独立的。 一般分布式系统要设计成允许出现部分故障而不影响整个系统的正常使用
- 并发: 为了更好的共享资源,系统中的每个资源都必须设计成在并发环境中是安全的。
- 透明性: 任何组件的故障,或者主机的升级、迁移,对于用户来说都是透明不可见的。
- 开放性: 由不同的程序来编写不同的组件,组件所发布的接口必须遵守一定的规范且能够被相互理解
- 安全性: 加密用于共享资源提供适当的保护,在网络上所有传递的敏感信息都需要进行加密
- 可扩展性: 系统要设计成随着业务量的增加,相应的系统也必须能扩展来提供对应的服务
线程
什么是线程
线程是程序执行流的最小单元。
一个标准的线程由 线程 ID、当前指令指针(PC)、寄存器集合和堆栈 组成
线程是进程中的一个实体,是系统独立调度和分派的基本单位。线程自己不拥有系统资源,只拥有一点儿在运行中必不可少的资源,
但它可与同属一个进程的其他线程共享进程所拥有的全部资源。
一个线程可以创建和撤销另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。
每个程序都至少有一个线程,若程序只有一个线程,那就是程序本身。
线程拥有三种基本状态
- 就绪: 线程具备运行的所有条件,逻辑上可以运行,在等待处理机
- 阻塞: 阻塞状态是指线程在等待一个时间(如某个信号量),逻辑上不可以执行。
- 运行: 运行状态是指线程战友处理机正在运行
线程是程序中一个单一的顺序控制流程,是进程内一个相对独立的、可调度的执行单元。在单个程序中同时运行多个线程完成不同的工作,称为 多线程。多数情况下,多线程能提升程序的性能。
进程和线程
进程和线程是并发编程的两个基本的执行单元。
线程,有时被称为轻量级进程(Lightweight Process, LWP)。
通信
进程间的通信是一切分布式系统的核心。
网络基础知识
OSI 参考模型
OSI 参考模型,即开放式通信系统互联参考模型(Open Systems Interconnection Reference Model)。OSI 模型把网路通信的工作分为7层:
- 物理层
- 数据链路层
- 网络层
- 传输层
- 会话层
- 表示层
- 应用层
OSI 分层的优点:
- 分层清晰、协议规范,易于理解和学习
- 层间的标准接口方便了工程模块化
- 创建了一个更好的互联环境
- 降低了复杂度,使程序更容易修改,产品开发的速度更快
- 每层利用紧邻的下层服务,更容易记住每个层的工能
TCP/IP 网络模型
TCP/IP 模型实际上是 OSI 模型的一个浓缩版本,它只有四个层次:
- 应用层(Application)–对应 OSI 的应用层、表示层、会话层
负责处理特定的应用程序细节,常用的通用应用有 Telnet(远程登录)FTP(文件传输协议) STMP简单邮件传输协议 SNMP(简单网络管理协议) - 传输层(Transport)–对应 OSI 的传输层
主要为两台主机上的应用程序提供端到端的通信。在 TCP/IP 协议簇中,有两个互不相同的传输协议:TCP(传输控制协议)和 UDP(用户数据报协议) - 网络层(Network)–对应 OSI 的网络层
处理分组在网络中的活动,例如分组的选路。在 TCP/IP 协议簇中,网络层协议包括IP协议(互联网协议)、ICMP 协议(互联网控制报文协议) 以及 IGMP 协议(互联网组管理协议) - 链路层(Link)–对应 OSI 的数据链路层和物理层
通常包括操作系统中的设备驱动程序和计算机中对应的网络接口卡。
TCP
TCP(Transmission Control Protocol)是面向连接的、提供端到端可靠的数据流(flow of data)。TCP 提供超时重发、丢弃重复数据、检验数据、 流量控制等功能,保证数据能从一端传到另一端。
UDP
UDP(User Datagram Protocol)不是面向连接的,主机发送独立的数据报(datagram)给其他主机,不保证数据到达。由于 UDP 在传输数据报前不用在客户和 服务器之间建立一个连接,且没有超时重发等机制,故而传输速度很快。
网路 I/O 模型的演进
同步和异步
同步和异步描述的是用户线程与内核的监护方式:
- 同步:是指用户线程发起 I/O 请求后需要等待或者轮询内核 I/O 操作完成后才能继续执行
- 异步:是指用户线程发起 I/O 请求后仍继续执行,当内核 I/O 操作完成后会通知用户线程,或者调用用户线程注册的回调函数。
阻塞和非阻塞
阻塞和非阻塞描述的是用户线程调用内核 I/O 操作的方式:
- 阻塞:是指 I/O 操作需要彻底完成后才返回到用户控件
- 非阻塞:是指 I/O 操作被调用后立即返回给用户一个状态值,无须等到 I/O 操作彻底完成
一个 I/O 操作其实分成了两个步骤:发起 I/O 请求和实际的 I/O 操作
阻塞 I/O 和非阻塞 I/O 的区别在于第一步,发起 I/O 请求时否会被阻塞,如果阻塞知道完成那么就是传统的阻塞 I/O,如果不阻塞,那么就是非阻塞 I/O。
同步 I/O 和异步 I/O 的区别就在于第二个步骤是否阻塞,如果实际的 I/O 读写阻塞请求进程,那么就是同步 I/O。
UNIX I/O 模型
UNIX下共有五种 I/O 模型:
- 阻塞 I/O
- 非阻塞 I/O
- I/O 复用(select 和 poll)
- 信号驱动 I/O(SIGIO)
- 异步 I/O(Posix.1)
深入了解可阅读: 《UNIX Network Programming, Volume 1, The Sockets Networking API(3rd Edition)》-W.Richard Stevens
远程过程调用(RPC)
进程间通信(Inter-Process Communication, IPC)
至少两个进程或线程间传送数据或信号的一些技术活方法。为了能使不同的进程互相访问资源并进行写作工作,才有了进程间通信。进程间的通信技术包括: 消息传递、同步、共享内存和远程过程调用。IPC是一种标准的 UNIX 通信机制。
过程调用的类型
在讨论客户/服务器(C/S)模型和过程调用时,主要有三种不同类型的过程调用:
- 本地过程调用(Local Procedure Call,LPC):指被调用的过程(函数)与调用过程处于同一个进程中。典型的情况是,调用者通过执行某条机器指令 把控制传给新过程,被调用过程保存机器寄存器的值,并在栈顶分配存放在其本地变量的空间
- 同主机间的远程过程调用(Remote Procedure Call,RPC):指被调用的过程与调用过程处于不同的进程中,但属于一台主机上。通常称调用者为客户, 被调用者的过程为服务器
- 不同主机间的远程过程调用:指一台主机上的某个客户调用另外一台主机上的某个服务器的过程
什么是远程过程调用
RPC 是远程过程调用的缩写。RPC 是指计算机 A 上的进程,调用另外一台计算机 B 上的进程,其中 A 上的调用进程被挂起,而 B 上的被调用 进程开始执行,当值返回给 A 时,A 进程继续执行。调用方可以通过使用参数将信息传送给被调用方,而后可以通过传回的结果得到消息。
RPC 的主要好处是双重的。
- 可以使用过程调用语义来调用远程函数并获取响应
- 简化了编写分布式应用程序的难度,隐藏了所有的网络代码存根函数
应用程序不必担心一些细节,比如 socket、端口号以及数据的转换和解析。在 OSI 参考模型中,RPC 跨越了会话层和表示层
实现远程过程调用
要实现远程过程调用,需要考虑以下几个问题:
- 传递参数
- 表示数据
- 传输协议
- 异常现象
- 语义
- 性能
- 安全性
面向消息的通信
一般是由消息队列系统(Message-Queuing System,MQ)或者面向消息中间件(Message-Oriented Middleware,MOM)提供高效可靠 的消息传递机制来进行平台无关的数据交流,并可基于数据通信进行分布系统的集成。通过提供消息传递和消息排队模型,可在分布式环境下扩展进程间的通信, 并支持多种通信协议、语言、应用程序、硬件和软件平台。
消息客户程序之间通过将消息放入消息队列或从消息队列中取出消息来进行通信。避免了网络通信的复杂性。消息队列和网络通信的维护工作 由 MQ 或者 MOM 完成。
常见的 MQ 或者 MOM 产品有 Java Message Service、Apache ActiveMQ、RocketMq、RabbitMQ、Apache Kafka、ZeroMQ(SaltStack)
一致性
分布式系统的一个重要问题是数据的复制。对数据进行复制一般为了增强系统的可靠性和提高性能。
以数据为中心的一致性模型
一致性模型是指进程和数据存储之间的一个约定
- 严格一致性(strict consistency)
任意读操作都要督导最新的写的结果;依赖于绝对的全局时钟。 - 持续一致性(continuous consistency)
区分不一致性的三个相互独立的坐标轴:- 副本之间的数值偏差
- 副本之间新旧程度偏差
- 更新操作顺序的偏差
这些偏差形成了持续一致性的范围。
- 顺序一致性(sequential consistency)
任何执行结果都是相同的,就好像所有进程对数据存储的读/写操作是按某种序列顺序执行一样,并且每个进程的操作按照程序所制定的顺序出现在这个序列中。 - 因果一致性(casual consistency)
所有进程必须以相同的顺序看到具有潜在因果关系的写操作。不同机器上的进程可以以不同的顺序看到并发的写操作。 相比顺序一致性,因果一致性去掉了没有联系的操作需要达成一直顺序观点的要求,保留了必要的顺序(有因果关系的) - 入口一致性(entry consistency)
对每个共享的数据定义一个同步变量(即:锁)。当然,没有进行同步就进行读操作,是无法保证正确结果的。
以客户为中心的一致性
以客户为中心的一致性就是以用户视角来看,数据是一致的。
- 单调读一致性(monotonic-read consistency)
- 单调写一致性(monotonic-write consistency)
- 读写一致性(read-your-writes consistency)
- 写读一致性(writes-follow-reads consistency)
容错性
任何一个组件的故障,都会导致 集中式系统 整个无法正常使用。而分布式系统区别于集中式系统的一个特性是它 容许 部分失效。
分布式系统设计中的一个重要目标:可以从部分失效中自动恢复,且不会严重地影响整体性能。
基本概念
容错往往与可靠的系统紧密相关,而可靠的系统需要满足以下需求:
- 可用性(Availability): 用来描述系统在给定时刻可以正确地工作
- 可靠性(Reliability): 指系统可以无故障地连续运行。与可用性相反,可靠性是根据时间间隔而不是任何时刻来进行定义的。
- 安全性(Safety): 指系统在偶然出现故障的情况下,能正确操作而不会造成任何灾难
- 可维护性(Maintainability): 发生故障的系统被恢复的难易程度。
容错,意味着即使系统发生了故障,还能正常提供服务。
故障分类
故障通常被分为三类
- 暂时故障(Transient fault): 只发生一次,然后就消失了,不再重现该故障
- 间歇故障(Intermittent fault): 发生,消失不见,而后再次发生,如此反复进行
- 持久故障(Permanent fault): 直到故障组件被修复之前持续存在的故障
分布式系统中的 典型 故障模式可以分为以下几种
- 崩溃性故障(Crash failure): 服务器停机,但是在停机之前工作正常
- 遗漏性故障(Omission failure): 服务器不能响应到来的请求。可以细分为:
- 服务器不能接受消息
- 服务器不能发送消息
- 定时性故障(Timing failure): 服务器对请求响应得过快或者过慢
- 响应性故障(Response failure): 服务器对请求以错误的方式进行了响应
- 任意性故障(Arbitrary failure): 服务器可能在任意的时间才生任意类型的故障。其中,任意类型故障是最严重的故障,也被称为拜占庭故障( Byzantine failure)。当发生故障时,服务器可能产生它从来没有产生过的输出,但是又不能检测出错误。更坏的情况是,发生故障的服务器恶意地与 其他服务器共同工作来产生恶意的错误结果。臭名昭著的 Windows 系统“蓝屏”,正是为了尽可能避免这种情况而设计的。
随意性故障与崩溃性故障紧密相关。崩溃性故障的一个典型例子就是操作系统崩溃。
使用冗余来掩盖故障
如果系统是容错的,那么它能做的最好的事情就是对其他进程隐藏故障的发生。关键技术是使用冗余来掩盖故障。有三种可能:信息冗余、时间冗余和物理冗余
- 信息冗余: 添加额外的位可使错乱的位恢复正常。也可以进行错误检测和纠正。当发生临时性或间歇性的错误时,时间冗余特别有用。TCP/IP 协议中 的重传机制是另外一个例子
- 物理冗余: 通过添加额外的设备或进程使系统作为一个整体来容忍部分组件的失效或故障成为可能
- 软件冗余: 确保当某些模块中的单个部件发生故障时,系统还可以正确的运行
分布式提交
在分布式系统中,事务往往包含多个参与者的活动,单个参与者的活动是能够保证 原子性 的,而保证多个参与者之间原子性则需要通过 两阶段提交 或者 三阶段提交 算法实现。
两阶段提交
两阶段提交协议(Two-phase commit protocol,2PC)的过程涉及协调者和参与者。协调者可以看做事务的发起者,同时也是事务的一个参与者。
-
第一阶段(准备阶段)
- 协调者节点向所有参与者节点询问是否可以执行提交操作(vote),并开始等待各参与者节点的响应。
- 参与者节点执行所有事务操作,并将 Undo 信息和 Redo 信息写入日志 若成功代表每个参与者已经执行了事务操作
- 各参与者节点响应协调者节点发起的询问。
-
第二阶段(提交阶段)
如果协调者收到参与者失败消息或者超时,直接给每个参与者发送回滚(Rollback)消息;否则,发送提交(Commit)消息;参与者根据协调者的指令执行 提交或者回滚操作,释放所有事务处理过程中使用的锁资源 必须在最后阶段释放锁资源不管最后结果如何,第二阶段都是结束当前事务。 两段式提交协议的优缺点:
- 优点:原理简单,实现方便
- 缺点:
- 同步阻塞。执行过程中,所有参与节点都是事务阻塞型的
- 单点故障。由于协调者的重要性,一旦协调者发生故障,参与者会一直阻塞下去
- 数据不一致。
- 无法解决的问题:协调者再发出 commit 消息之后宕机,而位唯一接收到这条消息的参与者同时也宕机了。那么即使协调者通过选举协议产生了 新的协调者,这条事务的状态也是不确定的,没人知道事务是否已经被提交
三阶段提交
三阶段提交协议(Three-phase commit protocol,3PC),与两阶段提交不同的是:
- 引入超时机制,同时在协调者和参与者都引入超时机制
- 在第一阶段和第二阶段中插入一个准备阶段,保证了在最后提交阶段之前各参与节点的状态是一致的。
3PC 把 2PC 的准备阶段再次一份为二,这样三阶段提交就有 CanCommit、PreCommit、Docommit
- CanCommit 阶段: 协调者向参与者发送 commit 请求,参与者如果可以提交就返回 Yes 响应,否则返回 No 响应。
- PreCommit 阶段: 协调者根据参与者的反应情况来决定是否可以执行事务的 PreCommit 操作。
- DoCommit 阶段: 进行真正的事务提交
三阶段提交不会一直持有事务资源并处于阻塞状态。但是这种机制也会导致数据一致性问题。
Paxos 算法
一种基于消息传递且具有高度容错特性的一致性算法。
在 Paxos 算法中,分为 4 种角色:
- Proposer: 提议者
- Acceptor: 决策者
- Client: 产生议题者
- Learner: 最终决策学习者。
CAP 理论
什么是 CAP 理论
CAP理论(也称为 Brewer 定理),理论观点是:在分布式计算机系统中不可能同时提供以下三个保证。
- 一致性(Consistency): 所有节点同一时间看到的是相同的数据
- 可用性(Availability): 不管是否成功,确保每一个请求都能收到响应
- 分区容错性(Partition tolerance): 系统任意分区后,在网路故障时,仍能操作

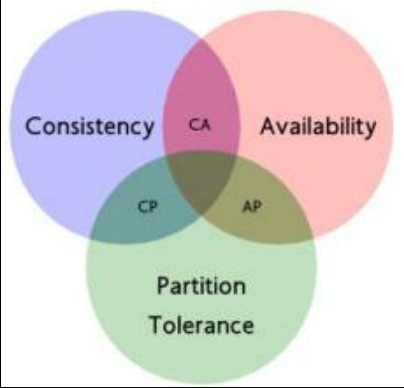
Choose 2 out of 3 (But not Consistency and Availability)
CAP常见模型
既然 CAP 理论已经证明了一致性、可用性、分区容错性三者不能同时达成。那么实际应用中,可以在其中的某一些方面放松条件,从而达到妥协。
-
牺牲分区(CA 模型)
牺牲分区容错性意味着把所有的机器放在一台机器内部,这违背了可伸缩性。- CA 模型常见的例子
- 单站点数据库
- 集群数据库
- LDAP
- xFS 文件系统
- 实现方式
- 两阶段提交
- 缓存验证协议
- CA 模型常见的例子
-
牺牲可用性(CP 模型)
牺牲可用性意味着一旦系统中出现分区这样的错误,系统直接就停止服务- CP 模型常见的例子:
- 分布式数据库
- 分布式锁定
- 绝大部分协议
- 实现方式:
- 悲观锁
- 少数分区不可用
- CP 模型常见的例子:
-
牺牲一致性(AP 模型)
- AP 模型常见的例子
- Coda
- Web 缓存
- DNS
- 实现方式
- 到期/租赁
- 解决冲突
- 乐观
- AP 模型常见的例子
CAP 最新发展
Eric Brewer 指出了 CAP 里面“ 三选二 ”的做法存在一定的误导性。主要体现在:
- 由于分区很少发生,那么在系统不存在分区的情况下没有理由牺牲 C 或 A
- C 与 A 之间的取舍可以在同一系统内以非常细小的粒度反复发生,而每一次的决策可能因为具体的操作,乃至因为牵涉特定的数据或用户而有所不同
- 这三种性质都可以在一定程度上衡量,并不是非黑即白的有或无。
相关推荐: 【Brewer 理论】
BASE
BASE(Basically Available、Soft state、Eventual consistency)来自于互联网的电子商务领域的实践,它是基于 CAP 理论逐步 演化而来。核心思想是即便不能达到强一致性(Strong consistency),但也可以根据应用特点采用适当的方式来达到最终一致性(Eventual consistency)的效果。BASE 是对 CAP 中 C 和 A 的延伸
安全性
计算机的安全性通常包括两个部分:认证和访问控制。
- 认证: 包括对有效用户身份的确认和识别。
- 访问控制: 避免对数据文件和系统资源的有害篡改。
基本概念
安全威胁、策略和机制
计算机系统中的安全性和可靠性密切相关。可靠性包括:可用性、可信赖性、安全性和可维护性。
- 安全威胁:
- 窃听: 一个未经授权的用户获得了对一项服务或数据的访问权限
- 中断: 服务或数据变得难以获得、不能使用、被破坏等情况。
- 修改: 对数据未经授权的改变或篡改一项服务以使其不再遵循其原始规范
- 伪造: 产生通常不存在的附加数据或活动
- 安全机制:
- 加密: 将数据转换为一些攻击者不能理解的形式
- 身份验证: 用于检验用户、客户、服务器等所声明的身份
- 授权: 授予客户执行该请求操作的权限
- 审计: 追踪各个客户的访问内容以及访问形式
密码与数字签名
加密包括使用密钥对数据进行编码,经过加密的数据称为密文,原始的数据称为明文。从密文到明文的转换过程称为解密。
加密算法
对称加密
指的是加密和解密算法都使用相同密钥的加密算法
1 | E(p, k) = C; D(C, k) = p |
对称加密算法的特点是: 算法公开、计算量小、加密速度快、加密效率高
常见的对称加密算法有: DES、3DES、TDEA、Blowfish、RC2、RC4、RC5、IDEA、SKIPJACK、AES等
使用对称密钥加密的数字签名
数字签名也称为信息摘要(Message Digest)或数字摘要(Digital Digest),是一个唯一对应一个消息或文本的固定长度的值,由一个单向 Hash 加密函数 对消息进行作用而产生。
常见的消息摘要算法有:MD2、MD4、MD5、SHA-1、SHA-256、RIPEMD128、RIPEMD160等
非对称加密
也称为公钥加密,由两个密钥组成。通常公钥使用 X.509实现。非对称加密与对称加密相比,安全性更好。
非对称加密的缺点:是加密和解密花费时间长、速度慢,只适合对少量数据机型机密。
常见的非对称加密算法:RSA、Elgamal、背包算法、Rabin、D-H、ECC(椭圆曲线加密算法)等
使用公钥加密的数字签名
对于数字签名的公钥加密使用 RSA 算法。
安全通道
SSL/TLS
SSL(Secure Sockets Layer,安全套接字层)是在网络上应用最广泛的加密协议实现。SSL 使用结合加密过程来提供网络的安全通信。
SSL 提供了一个安全的增强标准 TCP/IP 套接字用于网络通信协议。国际标准组织(Internet Engineering Task Force, IETF)管理后,SSL 更名 为 TLS(Transport Layer Security, 传输层安全)。
| TCP/IP 层 | 协议 |
|---|---|
| Application Layer | HTTP、NNTP、Telnet、FTP 等 |
| Secure Sockets Layer | SSL |
| Transport Layer | TCP |
| Internet Layer | IP |
SSL 握手过程
SSL 通过握手过程在客户端和服务器之间协商会话参数,并建立会话。会话包含的主要参数有:会话 ID、对方的证书、加密套件(密钥交换算法、数据加密算法 和 MAC 算法等)以及主密钥(master secret)。
SSL 存在三种握手过程情况:
- 只验证服务器的 SSL 握手过程
只需要验证 SSL 服务器身份,不需要验证 SSL 客户端身份 - 验证服务器和客户端的 SSL 握手过程
SSL 客户端的身份验证是可选的,由 SSL 服务器决定是否验证 SSL 客户端的身份 - 恢复原有会话的 SSL 握手过程
协商会话参数、建立会话的过程,需要使用非对称密钥算法来加密密钥、验证通信对端的身份,计算量较大,占用了大量的系统资源。为了简化 SSL 握手过程, SSL 允许已经协商过的会话。
HTTPS
HTTPS(Hyper Text Transfer Protocol over Secure Socket Layer)是基于 SSL 安全连接的 HTTP 协议。HTTPS 通过 SSL 提供的数据加密、 身份验证和消息完整性等安全机制,为 Web 访问提供了安全性保证,广泛应用于网上银行、电子商务等领域。
- 配置 SSL/TLS 以支 持HTTPS
相关推荐:
若是使用阿里云的 SSL 证书,可参考:
访问控制
访问控制是指按用户身份以及所归属的某项定义组来限制用户对某些信息项的访问,或限制对某些控制功能的使用的一种技术。
访问控制的功能:
- 防止非法的主题进入受保护的网络资源
- 允许合法用户访问受保护的网络资源
- 防止合法的用户对受保护的网络资源进行非授权的访问。
防火墙
一个由软件和硬件设备组合而成、在内部网和外部网之间、专用网和公共网之间的界面上构造的保护屏障。防火墙主要由服务访问规则、 验证工具、包过滤和应用网关4个部分组成,防火墙就是一个位于计算机和它所连接的网络之间的软件和硬件。
防火墙具备以下特性:
- 内部网络和外部网络之间的所有网络数据都必须经过防火墙
- 只有符合安全策略的数据流才能通过防火墙
- 防火墙自身应具有非常强的抗攻击免疫
- 应用层防火墙具备更细致的防护能力
- 数据库防火墙具有针对数据库攻击的阻断能力
堡垒机
在一个特定的网络环境下,为了保障网络和数据不受来自外部和内部用户的入侵和破坏,而运用各种技术手段实时收集和监控网络环境中每一个 组成部分的系统状态、安全事件、网络活动,以便集中报警、记录、分析、处理的一种技术手段。
总和了核心系统运维和安全审计管控两大主干功能。通过切断终端对网络和服务器资源的直接访问,而采用协议代理的方式,接管了终端 计算机对网络和服务器的访问。(安全审计是事前预防、事中预警的有效风险控制手段,也是时间追溯的可靠证据来源。)
拒绝服务
DoS(Denial of Service)攻击是指:通过向服务器发送大量垃圾信息或干扰信息的方式,导致服务器无法向正常用户提供服务的现象。对付一个或 多个资源的 DoS 往往比较高效,而要对付 DDoS(distributed denial of service, 分布式拒绝服务) 则要困难得多。
DDoS 攻击主要分为两类:
- 宽带耗竭的攻击: 向某个机器发送大量的消息,正常的消息很难到达接收者
- 资源耗竭的攻击: 使接收者把资源消耗在无用的消息上
常见的防止 DDoS 的方式:
- TCP 首包丢弃方案: 利用 TCP 协议的重传机制识别正常用户和攻击报文。当防御设备接到一个 IP 地址的 SYN 报文后,简单对比该 IP 是否存 在于白名单中,存在则转发到后端。
- 缓存: 尽量由设备的缓存直接返回结果来保护后端业务。也可以使用 CDN(Content Delivery Network,内容分发网络) 节点缓存内容。
- 重发: 可以直接丢弃 DNS 报文导致 UDP 层面的请求重发,也可以是返回特殊响应强制要求客户端使用 TCP 协议重发 DNS 查询请求。
- 判断报文内容: 一个 TCP 连接中,HTTP 报文太少或报文太多都是不正常的。
访问控制的模型
开发者需要在软件和设备中实现访问控制功能,访问控制模型为之提供了模型。
常见的访问控制模型有三种:
- 自主访问控制(Discretionary Access Control, DAC)模型: 由客体的属主对自己的客体进行管理,由属主决定是否其客体的访问权限或部分访问授权。 Linux 系统中有两种自主访问控制策略:一种是9位权限码(User-Group-Other),另一种是访问控制列表 ACL(Access Control List)
- 强制访问控制(Mandatory Access Control, MAC)模型: 将系统中的信息分密级和类进行管理,以保证每个用户只能访问到那些被标明可以访问的信息。
- 基于角色的访问控制模型(Role Based Access Control, RBAC)模型:管理员定义一系列角色(roles)并把它们赋予主体。RBAC 有基于规则的、 基于角色的访问控制(Rule-Based Role-Based Access Control, RB-RBAC)。包含了根据主体的属性和策略定义的规则动态地赋予主体角色的机制。
并发
计算机上同时执行多个程序。
线程与并发
线程允许在同一个进程中同时存在多个线程控制流,共享进程范围内的资源。同时还提供了直观的分解模式来充分利用操作系统中的硬件并行性。
多线程编程使程序任务并发成为了可能。而并发控制主要是为了解决多个进程之间资源争夺 等问题。
并发与并行
并发是同一时间应对(dealing with)多件事情的能力;并行是同一时间动手做(doing)多件事情的能力。
并发(concurrency)属于问题域(problem domain),并行(parallelism)属于解决域(solution domain)。并行和并发的区别在 于 有无 状态,并行计算适合无状态应用,而并发解决的是有状态的高性能;有状态要着力解决并发计算,无状态要着力并行计算,云计算要能做到这两种 计算 自动伸缩扩展。
并发带来的风险
多线程并发会带来如下的问题:
- 安全性问题: 线程间的通信主要是通过共享范文字段及其字段所引用的对象来实现的。但可能导致2种错误: 线程干扰(thread interference) 和内存一致性错误(memory consistency errors)
- 活跃度问题: 并行应用程序的及时执行能力被称为活跃度(liveness)。当某个操作无法继续执行下去,就会发生活跃度问题。串行程序 中,
活跃度问题形式之一就是 无限循环(死循环); 而在多线程中,常见的活跃度问题主要有 死锁、饥饿以及活锁。
- 死锁(Deadlock): 指两个或多个线程永远被阻塞,一直等待对方的资源。
- 饥饿(Starvation): 一个线程由于访问不足的共享资源而不能执行程序的现象。一般出现在共享资源被某些 “贪婪” 线程占用。
- 活锁(Livelock): 线程常常处于响应另一个线程的动作,如果其他线程也常常响应该线程的动作,那么就可能出现活锁。
- 性能问题: 当线程共享数据时,必须使用同步机制,但这会抑制某些编译器优化,使内存缓存区中的数据无效,以及增加内存的同步流量。
同步(Synchronization)
避免线程干扰和内存一致性错误。
- 线程干扰
多个线程访问共享数据时,可能由于“交错”,导致线程间访问的数据出现丢失或者异常。这种现象是不可预测的,线程间相互干扰造成的 bug 是很难定位和修改的。 - 内存一致性错误
发生在不同线程对同一数据产生不同的“看法”。避免出现这种错误的关键是理解 happens-before 关系。确保对内存的 写操作 对于其他特定的 语句是可见的。 - 内部锁和同步
同步是构建在被称为“内部锁(intrinsic lock)”或者是“监视锁(monitor lock)”的内存实体上。内部锁在两个方面都扮演着很重要的角色:保证对 对象状态访问的排他性,建立对象可见性相关的 happens-before 关系。每一个对象都有一个与之相关联动的内部锁。 - 同步方法中的锁
一个线程调用一个同步方法的是同,会自动获得该方法所属对象的内部锁,并在方法返回的时候释放该锁。即使由于出现了没有被捕获的异常而导致方法返回,该锁 也会被释放。 - 同步语句
创建同步代码的一种方式,和同步方法不同,使用同步语句必须致命使用具体的内部锁。 - 重入同步(Reentrant Synchronization)
线程不能获取已经被别的线程获取的锁。但是线程可以获取自身已经拥有的锁。允许一个线程能 重复获得一个锁 成为重入同步(reentrant synchronization)
原子访问(Atomic Access)
避免被其他线程干扰的做法的总体思路- -原子访问
- 在编程中,原子性动作就是指一次性有效完成的动作。
- 原子性动作不会出现交错,因此这些动作不用考虑线程间的干扰。但是,这不意味着可以移除对原子操作的同步,因为内存一致性错误还可能出现。
分布式系统架构体系
基于对象的体系结构
在基于对象的分布式体系中,对象的概念在分布式实现中骑着极其关键的作用。所有一切都可以被作为对象抽象出来,客户端将以调用对象的 方式来获取服务和资源。
分布式对象之所以成为重要的范型,是因为相对比较容易的把 分布的特性隐藏 在对象接口后面。
分布式对象
对象存储状态在字段(field)里,通过方法(methods)来暴露其行为。方法对对象的内部状态进行操作,并作为对象与对象之间通信的 主要机制。隐藏对象内部状态,通过方法进行所有的交互操作,这就是面向对象编程的一个基本原则- - 数据封装(data encapsulation) , 可以通过接口(interface)来使用方法。一个对象可能实现多个接口,而给定的一个接口定义可能有多个对象为其提供实现。
把接口与实现这些接口的对象进行分隔,对于分布式系统是至关重要的。将接口放在一台机器上,对象本身驻留在另外一台机器上。这种组织通常称为 分布 式对象(distributed object)。
当客户绑定(bind)到一个分布式对象时,就会把这个对象的接口实现(proxy,代理),然后加载进客户的地址空间中。
服务器端存根通常被称为骨架(skeleton),因为它提供了明确的方式,允许服务器中间件来访问用户定义的对象。
大多数分布式对象的一个特性是:它们的状态不是分布式的。状态驻留在单台机器上,在其他机器上,智能的使用被对象实现的接口,这样的对象也被称为 远程对象(remote object)。
微软 DCOM(COM+)
最初一种称为 OLE(Object Linking and Embedding) 的机制(允许一个程序动态连接其他库来支持其他功能),后来演变成了 COM (Component Object Model- -一个二进制文件)。其着眼于同一台机器上 不同应用程序之间的通信 请求。
DCOM(Distributed Component Object Model)是对 COM 的扩展,支持不同的两台机器上的组件之间的通信。后来更名为 COM+ 。
DCOM 最大的缺点:微软独家,在跨防火墙方面的工作做得不是很好(大多数 RPC 系统也有类似的问题),因为防火墙必须允许某些端口来 让 ORPC 和 DCOM 通过。
CORBA
Sun RPC,DCE 等远程过程调用的机制存在一些缺陷。面向对象语言期望在函数调用中体现多态性(不同类型的数据的函数的行为应该有所不同), 这恰恰是传统的 RPC 所不支持的。
CORBA(Common Object Request Broker Architecture) 是由 OMG 组织制定的一种标准的面向对象应用程序的体系规范。也可以说是 面向对象管理组织(OMG)为了解决分布式处理环境(DCE)中,硬件和软件系统的互联 而提出的一种解决方案。
CORBA 体系主要内容包括以下部分:
- 对象请求代理(Object Request Broker,ORB)
- 对象服务(Object Services)
- 公共设施(Common Facilitites)
- 应用接口(Application Interfaces)
- 领域接口(Domain Interfaces)
IDL(Interface Definition Language)用于指定类的名字、属性和方法。IDL编译生成代码来处理编组、解封以及 ORB 与网络之间的交互。 会生成客户机和服务器存根。
Java RMI
Java RMI(Remote Method Invocation,远程方法调用)。在创建分布式应用时,可以从其他 Java 虚拟机(JVM)调用远程对象的方法。 根据 Java 虚拟机的垃圾回收机制原理,在分布式环境下,服务器进程需要知道哪些对象不再由客户端引用。从而可以被删除(垃圾回收 dirty 和 clean 操作)。
面向服务的架构(SOA)
SOA 体系结构(Service Oriented Architecture,面向服务的架构)是基于服务组件模型,将应用程序的不同功能单元(服务)通过定义 良好的接口连接,接口采用中立方式进行定义,独立于实现服务的硬件平台、操作系统和编程语言,使得构建在系统中的服务可以统一、通用、灵活的方式进行交互。
SOA 组件模型的特点:
- 可重用
- 松耦合
- 明确定义的服务接口
- 基于开放标准
- 无状态的服务设计
架构 VS 标准
企业级中间件的标准同化企业应用程序“企业软件总线(Enterprise Software Bus,ESB)”。ESB 视图通过确定独立于软件模块间的、独立技术、 统一的企业级通信标准,从跟不上解决应用程序的继承问题。
SOA 架构独立于标准,提供了架构的蓝图。架构蓝图切开、分块和组合企业应用程序层,将组件“服务”化。
SOA 的基本概念
- SOA 的定义和组成
SOA 是一个软件架构,包含了四个关键概念:应用程序前端、服务、服务库和服务总线,一个服务包含一个合约、一个或多个接口以及一个实现。
组成关系图:
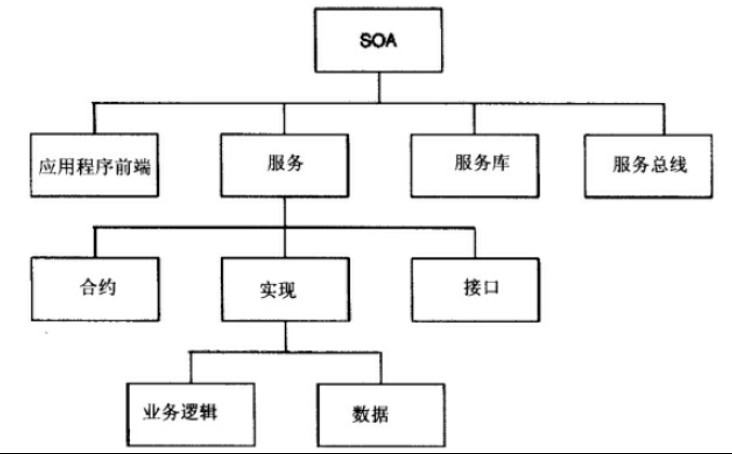
图片摘自分布式系统常用技术及案例分析
- SOA 的角色
SOA 架构中,有如下实体角色:- 服务请求者(Service Customer)
- 服务提供者(Service Provider)
- 服务管理中心(Service Management Center) SOA 体系结构的操作:
- 服务注册
- 服务寻址
- 服务交互(远程服务调用)
基于 Web Services 的 SOA
Web Services 是 SOA 架构系统的一个实例,在 SOA 架构实现中的应用非常广泛。
Web Services 的实现一般使用 Web 服务器作为服务请求的管道。客户端访问该服务,首先通过一个 HTTP 协议发送请求到服务器上的 Web 服务器。 Web 服务器配置是识别 URL 的一部分路径名或文件名后缀,并将请求传递给特定的浏览器插件模块。这个模块可以出去头、解析数据(如果需要),并根据需 要调用其他函数或模块。
- XML-RPC
将请求和响应封装解析为人类可读的 XMl 格式。 - SOAP
SOAP(Simple Object Access Protocol,简单对象访问协议)指定 XML 作为无状态的消息交互格式,包括了 RPC 式的过程调用。SOAP 只是一种消息格式,并未定义垃圾回收、对象引用、存根生成和传输协议。由于 SOAP 只是提供了标准化的消息结构,为了实现它需要用 WSDL (Web Services Description Language)来描述 Web Services 的方法。
WSDL包括以下部分:- 类型(Types)
- 消息(n/a)
- 接口(Interface)
- 绑定(Binding)
- 服务(Service)
- 终点(Endpoint)
- 操作(Operation)
- Microsoft .NET Remoting
提供了一种允许对象通过应用程序域与另一个对象进行交互的框架。在从一个应用程序域项另一个应用程序域传输消息时,所有 XML 编码都使用 SOAP 协议。 处于安全性方面考虑,远程处理提供了大量挂钩,使得在消息流通过通道进行传输之前,安全接收器能够访问消息和序列化对象。
.NET Remoting 对象- Single Call(单一调用对象)
- Singleton Objects(单一元素对象)
- Client-Activated Object(CAO,客户端激活的对象)
- 超越 SOAP
AJAX(Asynchronous JavaScript And XML,异步的 JavaS 和 XML)
Web 浏览器最初的设计是为 Web 页面提供非动态的交互模型。Web 服务器是建立在同步的请求-响应(request-response)上的交互模型。文档对象模型(Document Object Model)和 JavaScript 的出现,使得可以以编程的方式来更改 Web 页面的各个部分 AJAX 提供了以非阻塞方式与服务器进行交互,即允许底层 JavaScript 在等待服务器结果时,用户仍然可以与页面进行交互。
SOA 的演变什么是 Serverless 架构
随着 HTTP API、云服务、敏捷开发、持续交付、DevOps 理论的发展和时间,以及基于容器技术来部署应用后服务的日渐成熟,面向服务的架 构也在不断演变,其中包括 REST 风格的架构、微服务架构、 Serverless 架构等框架形式。
REST 风格的架构
什么是 REST
REST(Representation State Transfer, 表属性状态转移)描述了一个架构样式的网络系统。首次出现在2000年 Roy Fielding 的博士论文 《Architectural Styles and the Design of Network-based Software Architectures》。
REST API 应该具备以下条件(原文):
- 不应该依赖于任何通信协议,尽管要成功映射到某个协议可能会依赖于元数据的可能性、所选的方法等
- 不应该包含对通信协议的任何改动,除非是补充或确定标准协议中未规定的部分
- 应该将大部分的描述工作放在定义用于表示资源和驱动应用状态的媒体类型上,或定义现有标准媒体类型的扩展关系名和(或)支持超文本的标记
- 绝不应该定义一个笃定的资源名或层次结构(客户端和服务器之间的明显耦合)
- 永远不应该有那些会影响客户端的“类型化”资源
- 不应该要求有先验知识(prior knowledge),除了初始 URI 和适合目标用户的一组标准化的媒体类型(即,能被任何潜在使用该 API 的客户端理解)
REST 并非标准,而是一种开发 Web 应用的架构风格,也可以理解为一种设计模式。REST 基于 HTTP、URL 以及 XMl 这些广泛流行的协议和标准。
REST 有哪些特征
REST 指的是一组架构约束条件和原则。满足这些约束条件和原则的应用程序或设计就是 REST。
REST 应用时围绕“资源表述的转移(the transfer of representaions of resources)”为中心来做请求和响应的。数据和功能均被视为资源, 并使用同一的资源标识符(URI)来访问资源。
基于 REST 的 Web 服务遵循一些基本的原则,是的 RESTful 应用更加简单、轻量:
- 通过 URI 来标识资源- -系统中的每一个对象或资源都可以通过一个唯一的 URI 来进行寻址
- 统一接口- -遵循 RFC-2616 所定义的协议方式显示的使用 HTTP 方法,建立创建、检索、更新和删除
(CURD:Create、Retrieve、Update and Delete)操作与 HTTP 方法之间的一对一映射
- 若要在服务器上创建资源,应该使用 POST 方法
- 若要检索某个资源,应该使用 GET 方法
- 若要更新或者添加资源,应该使用 PUT 方法
- 若要删除某个资源,应该使用 DELETE 方法
- 资源多重表述- -URI 所访问的每个资源都可以使用不同的形式加以表示(比如 XML 或者 JSON)。
- 无状态- -对服务器端的请求应该是无状态的,完整、独立的请求不要求服务器在处理请求时检索任何类型的应用程序上下文或状态。
REST API 最佳实践
- 使用的名词而不是动词 使用名词来定义接口,不应该使用动词
- GET 方法和查询参数不能改版资源状态 如果要改变资源的状态,要使用 PUT、POST 或 DELETE
- 使用名词复数 不要混淆名词的单复数。保持简单,只用复数名词来定义所有资源
- 使用子资源来表达资源间的关系
- 使用 HTTP header 来序列化格式
客户端、服务端都需要知道相互之间的通信格式。这些格式可以定义在 HTTP header 里面:
- Content-Type 定义了请求格式
- Accept 定义了接收相应的格式列表
- 使用 HATEOAS 约束 HATEOAS(Hypermedia as the engine of application state)是 REST 架构风格中最复杂的约束,也是构建成熟 REST 服务的核心。
- 提供过滤、排序、字段选择、分页
- API 版本化 版本号使用简单的序号,并避免点符号
- 充分使用 HTTP 状态码来处理错误 在设计 API 处理错误时,应该充分使用 HTTP 状态码,而不是简单的抛出一个“500-Internal Server ERROR(内部服务器错误)”
微服务架构(MSA)
什么是 MSA
微服务架构(Microservices Architecture,MSA)的出现并非偶然,而是这个时代的软件思想、技术工具的发展有着密切的联系。
简言之,微服务架构风格就像是把小的服务开发成单一应用的形式,运行在其自己的进程中,并采用轻量级的机制进行通信(一般是 HTTP 资源 API)。 这些服务都是围绕业务能力来构建的,通过全自动部署工具来实现独立部署。这些服务可以使用不同的编程语言和不同的数据存储技术,并保持最小化集中管理。
MSA包含如下特征:
- 组件以服务形式来提供- -微服务也是面向服务的
- 围绕业务功能进行组织- -微服务更倾向于围绕业务功能对服务结构进行划分、拆解,是针对业务领域有着完整实现的软件,包含使用接口、持久存储以及 对应的交互。
- 产品不是项目- -微服务要求开发团队对软件产品的整个生命周期负责,这也正是 DevOps 的文化理念。
- 强化终端及弱化通道- -微服务的应用致力于松耦合和高内聚,更喜欢 REST 风格,或者采用轻量级消息总线(如 RabbitMQ 或 ZeroMQ 等)来发布消息
- 分散治理- -把整体式框架中的组件拆分成不同的服务
- 分散数据管理- -微服务让每个服务管理自己的数据库:无论是相同数据库的不同实例,或者是不同的数据库系统。
- 基础设施自动化- -云计算,减少构建、发布、运维微服务的复杂性。更加依赖于基础设施的自动化。
- 容错性设计- -微服务应为每个应用的服务及数据中心提供日常的故障检测和恢复
- 改进设计- -微服务所提供的服务应该能够替换或者报废,而不是要长久的发展。
MSA VS. SOA
SOA 需要对整个系统进行规范,而 MSA 的每个服务都可以有自己的开发语言、开发方式、灵活性大大提高。
-
单体架构
单体架构的当应用变大,团队增长,缺点就愈加明显:- 代码库庞大
- IDE 超载
- Web 容器超载
- 难于持续部署
- 难于伸缩应用
- 难于调正开发规模
- 需要对一个技术栈长期投入
-
微服务架构
一个微服务架构的应用或是多层架构的或是六角架构的,并且包含多种类型:- 表示组件(Presentation Components)- -响应处理 HTTP 请求,并返回 HTML 或 JSON/XML(对于 Web Service API 而言)
- 业务逻辑(Business logic)- -应用的业务逻辑
- 数据库访问逻辑(Database access logic)- -数据访问对象用于访问数据库
- 应用集成逻辑(Application integration logic)- -消息层
最终微服务架构的解决方案:
- 通过采用伸缩立方(Scale Cube),特别是 y 轴方向上的伸缩性来架构应用,将应用按功能分解为一组相互协作的服务的集合。每个服务实现一组有限 并相关的功能。
- 服务间通过 HTTP/REST 等同步协议或 AMQP 等异步协议进行通信
- 服务独立开发和部署
- 每个服务为了与其他服务器解耦,使用自己的数据库。必要时,数据库间的一致性通过数据库复制机制或应用级事件来维护
微服务的好处:
- 每个微服务都相对较小
- 易于开发者理解
- IDE 反应更快,开发更高效
- Web 容器启动更快,开发更高效,并提升了部署速度
- 每个服务都可以独立部署,易于频繁部署新版本的服务
- 易于伸缩开发阻止结构
- 提升故障隔离(fault isolation)
- 每个服务可以单独开发和部署
- 消除了任何对技术栈(technology stack)的长期投入(long-term commitments)
微服务的缺点:
- 开发者要处理分布式系统的额外复杂度
- 开发者 IDE 大多是面向构建单体架构的,并没有显式提供对开发分布式应用的支持
- 测试更加困难
- 开发者需要实现服务间通信机制
- 不使用分布式事务实现跨服务的用例更加困难
- 实现跨服务的用例需要团队间的细致写作
- 生产环境的部署复杂度高,对于包含多种不同服务类型的系统,部署和管理的操作复杂度仍然存在
- 内存消耗增加。微服务架构使用 N×M 个服务实例来替代 N 个单体架构应用实例。
何时采用 MSA
微服务使开发变得更简单、更快捷了。但是,微服务带来了一系列的非功能性要求,比如:事务、服务治理(注册、发现,负载,路由,认证授权,隔离)、 监控(日志,性能监控,告警,调用链路)、部署、测试 等。微服务依赖于“基础设施自动化”。
如何将系统分割为微服务:
- 通过动词或用例来分割
- 通过名称或资源来分割
理论上,每个服务应该只承担很小的职责。Bob Martin 讲过使用单一职责原则(SRP)来设计类。SRP 定义类的职责作为变化的原因, 而且类应该只有一个变化的原因。使用 SRP 来设计服务也是合理的。
另一种有助于服务设计的类比是 UNIX 使用工具的涉及方法。UNIX 提供了大量的使用工具如 grep、cat 和 find。每个工具只做一件事,通常做得非常好, 并且可以通过 管道 跟其他工具使用 shell 脚本组合来执行复杂任务。
容器技术
虚拟化技术
所谓虚拟化技术就是将事务从一种形式转变成另一种形式,最常用的虚拟化技术有操作系统中内存的虚拟化,也有虚拟专用网技术(VPN)在 公共网络中虚拟化一条安全、稳定的“隧道”。
虚拟机技术也是虚拟化技术的一种。
容器 VS. 虚拟机
容器具有轻量级特性,所需的内存空间较少,提供非常快的启动速度,而虚拟机提供了专用操作系统的安全性和更牢固的逻辑便捷。
容器提供了更高级的隔离机制,许多应用程序在主机操作系统下运行,所有应用程序共享某些操作系统库和操作系统的内核。容器和虚拟机都具有高度可移植性。
容器的一大好处是应用程序以标准方式进行了格式化之后才放到容器中。但是 Docker 容器里面的应用程序无法迁移到另一个操作系统。
- 成熟度方面比较
虚拟机是一项高度发展、非常成熟的技术;容器是新技术 - 启动速度比较
创建容器的速度比虚拟机要快得多,由于虚拟机必须从存储系统检索 10GB 至 20GB 的空间给操作系统。 - 安全方面比较
虚拟机比容器有更高的安全性 - 性能方面的比较
Docker 的性能等同于或超出 KVM 的性能。当使用 AUFS 存储文件时,Docker的性能会降低,使用卷(volume)能获得更好的性能。因为通过卷目录能够 绕过联合文件系统(union file system)。Docker默认的网络选项是--net=bridge,由于 NAT 会重写数据包,也引入了性能开销。可以使用--net= host来改善网络的性你能。从诞生以来,KVM 的性能有了很大的提升,但是仍不适合延时敏感或高 I/O 访问率的工作负载。
基于容器的持续部署
-
持续部署管道
持续部署管道(continuous-deployment pipeline)是指在每次代码提交时会执行的一系列步骤。
持续部署的意义不仅在于节省维护与 bug 修复的投入,还能更快的将新特性发布至生产环境中。缩短开发功能并交付给用户之间的时间。 -
测试(Testing)
传统的软件测试方式是对源代码进行单元测试。为了对特性进行验证,往往需要功能性测试。 -
构建(Building)
执行完所有测试,就可以开始创建容器。 -
部署(Deploying)
当容器上传至注册中心后,就可以在每次签入之后部署微服务。 -
蓝-绿部署(Blu-Green Deploying)
部署一个新发布,使其与就发布并行运行,可以先对新发布进行测试,随后再对代理进行重新配置,以指向新发布。需要考虑的是如何将用户的请求从旧的请求 发布重定向至新的发布。解决方案就是 服务发现。
服务发现包括三个部分:- 服务注册中心保存服务的信息
- 对新的服务进行注册,并撤销已中止的服务
- 通过某种方式获取服务的信息
通过服务发现功能,将部署与服务 IP 地址和端口信息保存,以便确定部署哪个版本。
-
运行预集成以及集成后测试
通过蓝绿部署,可以先将预发布版本部署至生产环境并进行测试,这称为“预集成(pre-integration)”测试。当预发布测试通过后,再重新配置代理,需要 进行“集成后(post-integration)”测试。需要验证的就是代理是否正确的配置。通常来说,只需对 80(HTTP)和 443(HTTPS)端口进行几次请求作为测试。 -
回滚与清理
在整个流程中任何一部分出错,整个环境应当保持与该流程尚未初始化之前相同的状态,即状态回滚(Rolling back)。 不论整个状态最终如何,都需要进行清理工作。需要停止新发布(失败)或旧发布(成功),并删除其注册信息。 -
决定每个步骤的执行环境
除部署相关的任务都应当在一个专属于持续部署的独立的集群中执行 -
完成整个持续部署流
在能可靠的将每次签入部署至生成环境中的前提下,需要对部署进行监控,并根据实时数据与历史数据进行相应的操作。 响应式恢复的要点在于通过工具进行数据收集、持续的监控服务,并在故障发生时采取行动。 预防性恢复需要将历史数据记录在数据库中,对各种模式进行评估,以预测未来是否会发生某些异常情况。
Serverless 架构
Serverless 是一种构建和管理基于微服务架构的完整流程,允许在服务部署级别而不是服务器部署级别来管理应用部署,甚至可以管理某个具体功能或 端口的部署,这就能让开发者快速迭代,更快速的交付软件。
这种新兴的 云计算 服务交付模式为开发人和管理员提供了合适的灵活性和控制级别。推动了 NoOps 模式的发展。
什么是 Serverless 架构
由于是新兴的架构,暂时还未有明确的定义。以下定义摘自 Serverless Architectures - Martin Folwer
- Serverless 最初用于描述那些显著地或完全地结合第三方、云托管的应用程序和服务来管理服务器端逻辑和状态的应用程序。这类服务被称为 BaaS ((Mobile) Backend as a Service,(移动)后端即服务)。
- 应用程序开发人员仍在编写服务器端逻辑的应用程序,但与传统体系结构不同,它在无状态容器中运行,可以由事件触发,短暂、完全的被第三方管理。 这类服务被称为是 FaaS(Functions as service,函数即服务)。
云计算的发展从 IaaS(Infrastructure as a Service,基础设施即服务)、PaaS(Platform as a Service,平台即服务)、SaaS (Software as a Service)软件即服务 到 BaaS。IaaS 将真实的物理机变成了虚拟机,PaaS 进一步将虚拟机变成了包含基础设施的中间件服务, BaaS 和 SaaS 将中间件服务扩展到更基础的后端能力。Serverless 这种无服务器架构,用服务代替服务器,无需了解落实服务,进一步提高了云计算的 成本和效率,从而为 BaaS 这种新时代云计算提供了架构基础。
要实现 Serverless 架构,需要以下技术和方案:
- 实现 BaaS 中的云代码特性,开发者可以直接开发在云端的业务代码,实现 FaaS
- 实现 API 网关,用 API 代表服务的入口,并对所有服务进行治理
- 微服务架构技术,用微服务的概念来实时服务的开发
- 利用 Docker 等容器技术部署运行微服务
Serverless 典型的应用场景
- UI 驱动的应用
- 消息驱动的应用(纯后台数据处理服务)
常见的 Serverless 框架
- AWS Lambda
- Google Cloud Functions
- Iron.io
- IBM OpenWhisk
- Serverless Framework
- Azure WebJobs
Serverless 框架原则
- 根据需要,使用计算服务来执行代码(没有服务器)
- 编写单一用途的无状态函数
- 设计基于推送的、事件驱动的管道
- 创建更粗实、更强大的前端
- 使用 第三方服务
- 根据需要,使用计算服务执行代码
所用自定义代码作为孤立的、独立的、一般是细粒度的函数来编写和执行,这些函数在无状态计算服务中运行。可能有时仍需要服务器来处理某个任务,但应该 尽量避免运行服务器并与之交互 - 编写单一用途的无状态函数
设计函数时应该尽量着眼于 单一职责原则(SRP)。拥有明确定义的接口的细粒度函数也更有可能在无服务器架构里面被重复使用。 - 设计基于推送的、事件驱动的管道
最灵活、最强大的无服务器设计是事件驱动型的。 - 创建更粗实、更强大的前端
拥有调用服务的更丰富的前端有利于更好的用户体验。在线资源之间更少的缓解和缩短的延迟会让人觉得应用程序的性能和可用性更好。数字签名的令牌让前端可以 与不同的服务(包括数据库)直接进行通信。但是不是一切服务都可以或者应该在前端执行。有些私密信息必须计算服务来协调动作、验证出具,并实施安全。 - 用包第三方服务
- 例子:使用 Serverless 实现游戏全球同服(详情请阅读原文)
分布式消息服务
Apache ActiveMQ
Apache ActiveMQ 是一个消息中间件(Message-oriented middleware, MOM),支持多种语言客户端,多种协议,以及 良好的 Spring 支持。同时支持异步通信。
Apache ActiveMQ 简介
ActiveMQ 是一个完全支持 JMS1.1 和 J2EE1.4 规范的 JMS Provider 实现。
Apache ActiveMQ 安装配置
推荐文章:
RabbitMQ
RabbitMQ 是消息代理(message broker),一个消息传递的中介。
RabbitMQ 简介
RabbitMQ 通常用于应用程序之间或程序的不同组件之间通过消息来集成。主要的原理十分简单,就是接受和转发消息。
由 LShift 提供的一个 Advanced Message Queuing Protocol(AMQP)的开源实现。
RabbitMQ 具有以下特点:
- 可靠: 提供了多种功能,可以权衡性能与可靠性,包括持久性、传输确认、发布者证实以及高可用性。
- 灵活的路由: 消息再到达队列前会通过 exchange(消息交换机)进行路由。
- 集群: 在本地网络上多个 RabbitMQ 服务器可以聚集,形成的单元逻辑 broker
- 联邦(federation): 需要更加松散和允许比集群服务器更不可考的连接
- 高可用的队里: 队列可以在多态计算机集群中配置为镜像
- 多协议: 支持在各种消息传递协议中传输
- 多样的客户端: 能想到的任何一种语言的客户端
- 简单易用的管理界面: 基于浏览器的 Web 管理界面,可以监视和控制消息代理
- 跟踪: 支持跟踪,方便查找问题
- 插件系统: 支持多种插件,以及可以编写自定义插件
- 商业支持: 提供商业支持、培训、咨询
- 强大的社区: 社区帮助
RabbitMQ 安装配置
RabbitMQ 使用
- Work Queues(工作队列)又叫作 Task Queues(任务队列),主要的思想是避免立即处理一个资源密集型任务造成的长时间等待。将任务分装成消息发送 到队列中。一个 worker(工作者)进程在后台运行,获取任务并最终执行任务。
- Publish/Subscribe(发布/订阅)在消息队列中是一种比较常见的工作模式,定义类如何向一个内容节点发布和订阅消息,内容节点也叫主题(topic), 主题是为发布者(publisher)和订阅者(subscribe)提供传输的中介。Publish/Subscribe 模型使发布者和订阅者之间不需要直接通信(如 RMI)就可 保证消息的传送,有效解决了系统间耦合问题。同时也定义了一种一对多的依赖关系,让多个订阅者对象同时监听某一个主题内容。
- Routing(路由)意味着在消息订阅中,可选择性的只订阅部分消息。
- Topics 类型的 exchange 拥有比 rirect 类型更多的灵活性。
- RPC,在 RabbitMQ 里实现 RPC(远程过程调用)
推荐文章:
RocketMQ
RocketMQ 简介
RocketMQ 是阿里巴巴出品的一款低延迟、可靠、可扩展、易于使用的面向消息的中间件。 RocketMQ 提供了如下功能:
- 支持 Pub/Sub 和 P2P 消息模型
- 在同一个队列中具有可靠的 FIFO 和严格的通信顺序
- 长 pull queue 模型,也支持 push 消费方式
- 在的那个队列中具备堆积上亿条消息的能力
- 覆盖多种消息协议
- 每个消息至少投递一次的 Message delivery semantics(消息传递语义)来保证分布式部署架构高可用
- 支持 Docker 镜像来进行隔离测试和分隔离集群
- 提供用于配置、测量和监控的功能丰富的管理界面
- 消息全链路跟踪
- 生产者事务消息机制,使得生产者和本地数据库事务能在一个原子操作里面进行处理
- 消息调度交付,类似 JMS2 规范的延迟交付
RocketMQ 安装
RocketMQ 最佳实践
推荐文章:
Apache Kafka
Apache Kafka 是一种高吞吐量的分布式发布订阅消息系统,可以提供消息的持久化,即使数据以 TB 的消息存储也能够保持长时间 的稳定性能。同时支持 Hadoop 并行数据加载。
Apache Kafka 简介
由 Apache 软件基金会开发的一个开源消息系统项目。项目的目标是为处理实时数据系统提供一个统一、高通量、零等待的平台。
Apache Kafka 的几个基本术语:
- Topic(主题)-- 按照分类对信息源进行维护,同时保存消息的信息,可以在多个节点上被分区和覆盖
- Producer(生产者)–把发送消息(写入数据)到 topic 中的进程叫作生产者
- Consumer(消费者)–把从 topic 中订阅消息(读取数据)的进程叫作消费者
- Broker(Kafka服务)-- 集群中的每个服务叫作 broker
服务端和客户端的通信是常见的 TCP 协议。支持多种语言的客户端。支持的数据格式包括 String、JSOn、Avro。
Kafka 设计中将每一个主题分区当做一个具有顺序排列的日志。同处于一个分区中的消息被设置了一个唯一的偏移量。只会保持跟踪未读消息。Kafka 的 生产者负责在消息队列中对生产出来的消息保证一定时间的占有,消费者负责追踪每一个主题(可以理解为一个日志通道)的消息并及时获取。因此,Kafka 可以在 消息队列中保存大量的开销很小的数据,并支持大量的消费者订阅。
Apache Kafka 的核心概念
-
Topic 和日志
一个 topic 是对一组消息的归纳。对每个 topic,Kafka 对它的的日志进行了分区,每个分区都是由一系列有序的、不可变的消息组成。每个消息都有一个 连续的叫作 offset(由 Consumer 维护) 的序列号,用来在分区中唯一的标识这个消息。在一个 可配置 的时间段内,Kafka 集群保留所有发布的消息。
将日志分区的目的:每个日志的数量不会太大,可以在单个服务上保存;可以单独发布和消费,为并发操作 topic 提供了一种可能。
-
分布式
每个分区在 Kafka 集群的若干服务中都有副本,这样就可以共同处理数据和请求,副本数量是可以配置的。副本使 Kafka 具备了容错能力。每个分区都有一个服务器作为“leader”,零或若干个服务器作为“follower”。leader 负责处理消息的读和写,follower 则复制 leader。 如果 leader 宕机了,follower 中的一台则会自动成为 leader。集群中的每个服务都会同时扮演两个角色: 作为它所持有的一部分分区的 leader, 同时作为其他分区的 follower,这样集群就会具有较好的负载均衡。
-
Producer
Producer 将消息发布到指定的 topic 中,并负责决定发布到哪个分区。通常简单的有负载均衡机制随机选择分区,但也可以通过特定的分区函数选择分区。 一般来说,使用更多的是第二种 -
Consumer
发布消息通常有两种模式:queue(队列)模式和 publish-subscribe(发布-订阅)模式。
在 queue 模式中,Consumer 可以同时从服务端读取消息,每个消息只被其中一个 Consumer 读到;在 publish-subscribe 模式中,消息被广播到 所有的 Consumer中。Consumer 可以加入到一个 Consumer Group(数量不能多于分区的数量),共同竞争一个 topic,topic 中的消息将被 分发到 Consumer Group 中的一个成员中。- 所有的 Consumer 在一个 Group 中,这是传统的 queue 模式,在各 Consumer 中实现负载均衡
- 所有的 Consumer 在不同的 Group 中,这是 publish-subscribe 模式,所有的消息都被分发到所有 Consumer 中。
- 同一 Group 中的 Consumer可以在不同的程序中,也可以在不同的机器上。
相比传统的消息系统(并发消费导致顺序错乱),Kafka 可以很好的保证有序性(只能保证在一个分区之内消息的有序性)。
-
保障
由 Producer 发送到一个特定的 Topic 分区的消息将按它们被添加时的顺序来发送;
Consumer 实例以日志中存储的顺序来查看消息;
对于复制因子 N 的 topic,将能承受最多 N-1 服务器的故障,而不会丢失提交到日志的任何消息。
Apache Kafka 的使用场景
- 消息
kafka 相较传统的消息系统,有更好的吞吐量、内置分区、副本和故障转移,这有利于处理大规模的消息;
消息往往用于较低的吞吐量,但需要低的端到端延迟,并需要提供强大的耐用性的保证。 - 网站活动追踪
Kafka 设计最初就是用于用户的活动追踪,将网站的活动(网页游戏、搜索或其他用户的操作信息)发布到不同的话题中心,这些消息可实时处理,实时监测, 也可加载到 Hadoop 或离线处理数据仓库。 - 指标
常用于检测数据,将分布式应用程序生成的统计数据集中聚合。 - 日志聚合 用 Kafka 代替一个日志聚合。
- 流处理
Kafka 消息处理包含多个阶段。其中原始输入数据从 Kafka 主题开始消费,然后汇总、丰富或者以其他的方式处理转化为新主题。这种处理是基于单个主题的 实时数据流。
除了 Kafka Streams,还有 Apache Storm 和 Apache Samza 可选择来进行流处理。 - 事件采集
是一种应用程序的设计风格,其中状态的变化可以根据时间的顺序记录下来。 - 提交日志
可以作为一种分布式的外部提交日志。日志帮助节点之间复制数据,并作为失败的节点来恢复数据重新同步。
Apache Kafka 的安装、配置、使用
相关推荐:
分布式计算
MapReduce
MapReduce 简介
MapReduce 是一个编程模型,用于大规模数据集(TB 级)的并行运算。
《MapReduce: Simplified Data Processing on Large Clusters》这篇文章描述了 Google 如何分割、处理、整合令人 难以置信的大数据集。
MapReduce 模型隐藏了并行、容错、本地优化以及负载平衡的细节。由于 MapReduce 的实现符合“有数千台机器组成的大集群”,有效利用了机器资源, 所以非常适合解决许多大型计算问题。
相关文章
MapReduce 的编程模型
MapReduce 的根本原理就是将大的数据分成小块逐个分析,然后将提取出来的数据汇总分析,最终获取需要的内容。
核心:Map(映射)和 Reduce(规约)
MapReduce 的实现
-
MapReduce 概述
通过自动分割将输入数据分成一个有 M 个 split的集,map 调用备份不到多台机器上。输入的 split 能够在不同的机器上被并行处理。通过用分割函数 分割中间 key,来形成 R 个片(例如,hash(key) mod R),reduce 调用备份不到多台机器上。分割数量(R)和分割函数由用户来指定。
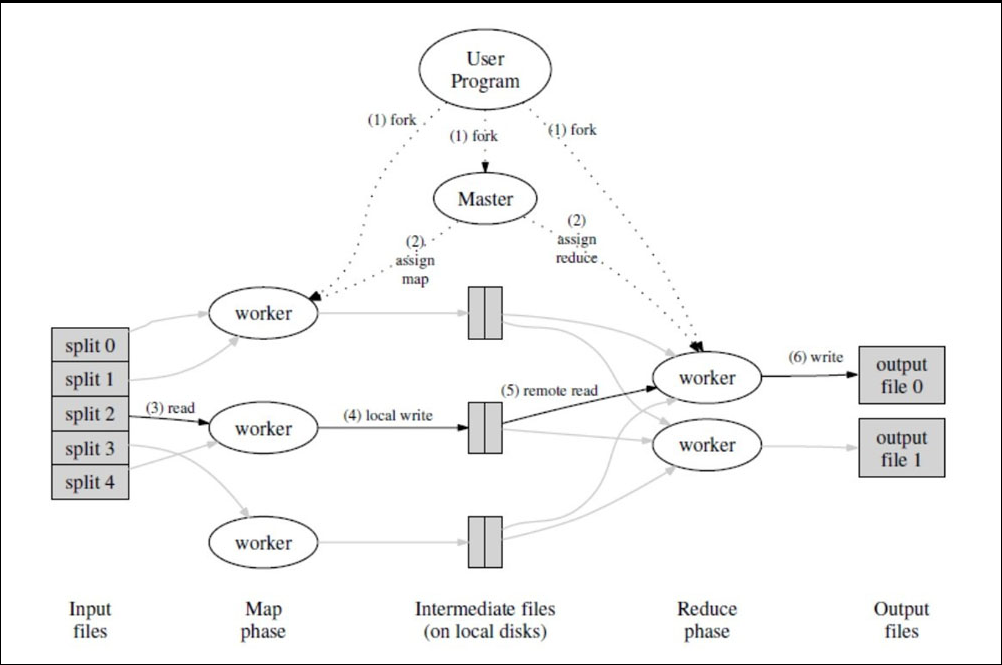
MapReduce 操作的全部流程:
当用户的程序调用 MapReduce 的函数时,将发生下面一系列动作(下面的序号和上图的数字标签相对应):- (1) 用户程序里的 MapReduce 库首先将输入文件分割成 M 个片,每个片的大小一般从 16MB 到 64MB(用户可以通过可选的参数来控制)。然后在 集群中开始大量的复制程序
- (2) 程序副本中的一个是 master,其他都是由 master 分配任务的 worker。有 M 个 map 任务和 R 个 reduce 任务将被分配。master 分配 一个map 任务或 reduce 任务给一个空闲的 worker
- (3) 一个被分配了 map 任务的 worker 读取相关输入 split 的内容。从输入数据中分析出 key/value 对,然后把 key/value 对传递给用户定 义的 map 函数。由 map 函数产生的中间 key/value 对被缓存在内存中
- (4) 缓存在内存中的 key/value 对被周期性的写入到本地磁盘,通过分割函数将其写入 R 个区域。在本地磁盘上的缓存对的位置被传送给 master, master 负责把这些位置传送给负责 reduce 的 worker
- (5) 当一个 reduce worker 得到 master 的位置通知时,它使用远程过程调用(RPC)来从 map worker 的磁盘上读取缓存的数据。当 reduce worker 读取了所有的中间数据后,通过排序使具有相同 key 的内容聚合在一起。因为许多不同的 ky 映射到相同的 reduce 任务,所以 排序是必须的。如果中间数据比内存还大,那么还需要一个外部排序
- (6) reduce worker 迭代排过序的中间数据,对于遇到的每一个唯一的中间 key,把 key 和相关的中间 value 传递给用户自定义的 reduce 函数。 reduce 函数的输出被添加到这个 reduce 分割的最终输出文件中
- (7) 当所有的 map 和 reduce 任务都完成了,master 唤醒用户程序。在这个时候,在用户程序里的 MapReduce 调用返回到用户代码。
-
master 的数据结构
master 保持了一些数据结构。它为每一个 map 和 reduce 任务存储它们的状态,其状态包括* idle(空闲)、in-progress(工作中)和 completed; 同时也存储了 worker 机器(非空闲任务的机器)的标识。
master 就像一个管道,通过它,中间文件区域的位置从 map 任务传递到 reduce 任务。因此,对于每个完成的 map 任务, master 存储由 map 任务生产 的 R 个中间文件区域的大小和位置。当 map 任务完成的时候,位置和大小的更新信息被接收。这些信息被逐步增加的传递给那些正在工作的 reduce 任务 -
容错
-
worker 失效
master 周期性的 ping 每个 worker。若果 master 在一个确定的时间段内没有收到 worker 相应的信息,那么它将把这个 worker 标记成失效。 因为每一个由这个失效的 worker 完城的 map 任务被重新设置成它初始的空闲状态,所以它可以被安排给其他的 worker。同样,每一个在失败的 worker 上正在运行的 map 或 reduce 任务也被重新设置成 idle 状态,并且将被重新调度。
在一个失效机器上已经完成的 map 任务将被再次执行,因为它的输出存储在它的磁盘上,所以不可访问。已经完成的 reduce 任务将不会被再次执行, 因为它的输出存储在全局文件系统中。
当一个 map 任务首先被 worker-A 执行之后,由于 A 失效了,所以又被 B 执行了,重新执行这个情况被通知给所有执行 reduce 任务的 worker。 任何还没有从 A 中读数据的 reduce 任务将从 worker-B 中读取数据。
MapReduce 可以处理大规模 worker 失效的情况。 -
master 失效
让 master 监控线程同期性的设置上文所述的 master 数据结构检查点是很容易的。如果这个 master 任务失效了,可以从上次最后一个检查点开始 启动另一个 master 进程。然而,因为只有一个 master,所以它的失效是比较麻烦的,因此现在的实现是:如果 master 失效,就中止 MapReduce 计算。客户可以检查这个状态,并且可以根据需要重新执行 MapReduce 操作。
-
在失效面前的处理机制
当用户提供的 map 和 reduce 操作对它的输出值是确定的函数时,我们的分布式实现将产生和全部程序无措状态下顺序执行一样的输出结果。
通过 map 和 reduce 任务输出所进行的原子提交来实现上面的特性。每个 in-progress 状态的任务把它的输出写到私有临时文件中。一个 reduce 任务产生一个这样的问津,而一个 map 任务产生 R 个这样的文件(一个 reduce 任务对应一个文件)。当一个 map 任务完成的时候,worker 发送一 个消息给 R 这个临时文件的名字。如果 master 从一个已经完成的 map 任务再次收到一个完成的消息,它将忽略这个消息;否则,它在 master 的 数据结构里记录这个 R 个文件的名字。
当一个 reduce 任务完成的时候,这个 reduce worker 原子的把临时文件重命名成最终的输出文件。如果相同的 reduce 任务在多个机器上执行, 多个重命名调用将被执行,并产生相同的输出文件。依赖由底层文件系统提供的原子重命名操作,来保证最终的文件系统状态仅仅包含一个 reduce 任务 产生的数据。
map 和 reduce 操作大部分是确定的,并且处理机制等价于一个顺序的执行,这很容易理解程序的行为。当操作不确定的时候,提供了比较若但是合理的 处理机制。当一个非确定操作的前面,一个 reduce 任务 R1 的输出等价于一个非确定程序执行产生的输出。然而,一个不同的 reduce 任务 R2 的 输出也许符合一个不同的非确定顺序程序执行产生的输出。
设定 e(Ri)为已经提交的 Ri 的执行(有且仅有一个这样的执行)。出现这个比较弱的语义,是因为 e(Ri)也许已经读取了由 M 的执行产生的输出, 而 e(Ri)也许已经读取了由 M 的不同执行产生的输出 -
存储位置
网络宽带是一个相当缺乏的资源,所以会把输入数据(由 GFS 管理)存储在机器的本地磁盘上来保存网络带宽。GFS 把每个文件分成 64MB 的一下块, 然后每个块的几个副本存储在不同的机器上(一般是3个副本)。MapReduce 的 master 考虑输入文件的位置信息,并努力在一个包含相关输入数据的机 器上安排一个 map 任务。如果这样做失败了,它尝试在那个任务的输入数据的附近安排一个 map 任务。
-
任务粒度
将 map 阶段细分成 M 个片,reduce 阶段分成 R 个片。M 和 R 应当比 worker 机器的数量大许多。每个 worker 执行许多不同的工作来提供动态 负载均衡,也可以加速从一个 worker 失效中恢复,这个机器上的许多已经完成的 map 任务可以被分配到所有其他的 worker 机器上。
在实现里 M 和 R 的范围是有大小限制的,因为 master 必须做 O(M + R)此调度,并且保存 O( M * R)个状态在内存中(这个因素使用的内存 很少的在 O(M*R)个状态片里,大约每隔 map 任务/reduce 任务对使用一个字节的数据)
R 经常被用户限制,因为每一个 reduce 任务最终都是一个独立的输出文件。实际上,更倾向于选择 M,以便每一个单独的任务大概都是 16MB 到 64MB 的输入数据(以便上面描述的位置优化是最有效的),把 R 设置成希望使用的 worker 机器数量的小倍数。 -
备用任务
“straggler(落后者)”是延长 MapReduce 操作时间的主要原因之一:一个机器需要花费一个异乎寻常的长时间来完成最后一些 map 或 reduce 任务中的一个。有很多原因产生 straggler。
有一个一般的机制来减轻这个 straggler 导致的影响。当一个 MapReduce 操作将要完成的时候,master 调度备用进程来执行那些剩下的 in-progress 状态的任务。无论是原来的还是备用的执行完成了,工作都被标记成完成。这个机制,通常只会多占用几个百分点的机器资源,却可以显著的减少完成大规模 MapReduce 操作的时间。
MapReduce 的使用技巧
- 分割函数
MapReduce 用户指定 reduce 任务和 reduce 任务需要的输出文件的数量。在中间 key 上使用分割函数,使数据分割后通过这些任务。一个默认的分割函数 是使用 hash 方法,从而达到非常平衡的分割。 - 顺序保证
保证在一个给定的分割里面,中间 key/value 对以 key 递增的顺序处理。 - Combiner 函数
在某些情况下,允许中间结果 key 重复会占据相当的比重,每个 map 任务将产生成百上千这样的记录。所有的技术将通过网络被传输到一个单独的 reduce 任 务,然后由 Reduce 函数加载一起产生一个数字。
在每一个执行 map 任务的机器上 Combiner 和 Reduce 函数都会被执行。一般来说,相同的代码被用在 Combiner 和 Reduce 函数中。Combinger 和 Reduce 函数之间唯一的区别是 MapReduce 库怎样控制函数的输出。Reduce 函数的输出被保存在最终输出文件里。Combiner 函数的输出被写到中间文件里, 然后被发送给 reduce 任务。 - 输入/输入出类型
MapReduce 库支持读取输入数据的格式:输入(输入分片与记录、文件输入、文本输入、二进制输入、多文件输入、数据库输入),输出( TextOutputFormat-默认输出、二进制输出、SequenceFileOutputFormat、多文件输出、SequenceFileAsBinaryOutputFormat、 MapFileOutputFormat、DBOutputFormat)。参考文章 - 副作用
在 Map 和/或 Reduce 操作过程中增加辅助的输出文件会比较省事。依靠程序 writer 把这种“副作用”变成原子的和幂等的。通常应用程序首先把输出结果 写到一个临时文件中,在输出全部数据之后,使用系统级的原子操作 rename 重新命名这个临时文件。 - 跳过错误记录
有时候因为代码里有 bug ,导致在某一个记录上 Map 或 Reduce 函数突然 crash 掉。
每个 worker 程序安装一个信号处理器来获取内存段异常和总线错误。在调用一个用户自定义的 Map 或 Reduce 操作之前,MapReduce 库把记录的序列号 存储在一个全局变量里。 - 本地执行
为了简化调试和测试,开发了一个可替换的实现,即在本地执行所有的 MapReduce 操作。 - 状态信息
master 运行了一个内置的 HTTP 服务器,并且可以输出一组状况页来供用户使用。 - 计数器
用来计算各种事件的发生次数。来自不同 worker 机器上的计数器值被周期性的传送给 master (在 ping 响应里)。部分计数器值被 MapReduce 库自动 维护。
Apache Hadoop
Apache Hadoop 是一个由 Apache 基金会开发的分布式系统基础架构。
Apache Hadoop 框架允许用户使用简单的编程模型来实现计算机集群的大型数据集的分布式处理。其本身被设计成在 应用层 检测和处理 故障的库,对于计算机集群来说,其中每台机器的顶层都被设计成可以容错的,以便提供一个高度可用的服务。
Apache Hadoop 框架最核心的设计是: HDFS 和 MapReduce。HDFS 为海量的数据提供了存储,而 MapReduce 则 为海量的数据提供了计算。
Apache Hadoop 简介
Apache Hadoop 主要有以下的优点:
- 高可扩展性:按位存储和处理数据的能力值得信赖
- 高扩展性:在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便的扩展到数以千计的节点中
- 高效性:能够在节点之间动态的移动数据,并保证每个节点的动态平衡
- 高容错性:能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配
- 低成本:项目是开源的
Apache Hadoop 核心组件
Apache Hadoop 包含以下模块:
- Hadoop Common- -常见使用模块,用来支持其他 Hadoop 模块
- Hadoop Distributed File System(HDFS)- -分布式文件系统,提供对应用程序数据的高吞吐量访问
- Hadoop YARN- -一个作业调度和集群资源管理框架
- Hadoop MapReduce- -基于 YARN 的大型数据集的并行处理系统
其他与 Apache Hadoop 相关的项目:
- Ambari- -一个基于 Web 的工具,用于配置、管理和监控 Apache Hadoop 集群,其中包括支持 Hadoop HDFS、Hadoop MapReduce、Hive、 Hcatalog、HBase、ZooKeeper、Oozie、Pig 和 Sqoop。还提供了仪表盘用于查看集群的健康,并能以用户友好的方式来查看 MapReduce、Pig 和 Hive 应用,方便诊断其性能。
- Avro- -数据序列化系统
- Cassandra- -可扩展的、无单点故障的多主数据库
- Chukwa- -数据采集系统,用于管理大型分布式系统
- HBase- -一个可扩展的分布式数据库,支持结构化数据的大表存储
- Hive- -数据仓库基础设施,提供数据汇总以及特定的查询
- Mahout- -一种可扩展的机器学习和数据挖掘库
- Pig- -一个高层次的数据流并行计算语言和执行框架
- Spark- -Hadoop 数据的快速和通用计算引擎。Spark 提供了简单和强大的变成模型用以支持广泛的应用,其中包括 ETL、机器 学习、流处理和图形计算
- TEZ- -通用的数据流编程框架,建立在 Hadoop YARN 之上,可以执行任意 DAG 任务,以实现批量和交互式数据的处理。
- ZooKeeper- -高性能的分布式应用程序协调服务
Apache Hadoop 安装配置
相关推荐:
Apache Spark
Apache Spark 是一个快速和通用集群计算系统。提供 Java、Scala、Python 和 R 等语言的高级 API,支持通用执行图 计算的优化引擎。还支持丰富的更高级别工具,包括执行 SQL 和处理结构化数据的 Spark SQL,机器学习的 Mlib,进行图形处理的 GraphX,以及 Spark Streaming。
Apache Spark 简介
Apache Spark 有如下特点:
- 快速
Apache Spark 具有支持循环数据流和内存计算的先进的 DAG 执行引擎,所以比 Hadoop MapReduce 在内存计算上快100倍,在硬盘就算快10倍。 - 易于使用
提供了超过 80 个高级的操作,可以轻松构建并行应该用程序。 - 全面
提供了 Spark SQL,机器学习的 Mlib,进行图形处理的 GraphX,以及 Spark Streaming 等库。 - 支持多环境
可以使用它的 standalone cluster mode 运行 EC2,Hadoop YARN、或者 Apache Mesos中。可以访问 HDFS、Cassandra、HBase、Hive、 Tachyou,以及任意的 Hadoop 数据源。
Apache Spark 与 Apache Hadoop 的关系
- 解决问题的层面不同
Apache Spark 与 Apache Hadoop 两者都是大数据框架。Hadoop 实质上更多是一个分布式数据基础设施:将巨大的数据集分派到一个由普通计算机组成的 集群中的多个节点进行存储。Hadoop 还会索引和跟踪这些数据,让大数据处理和分析效率达到前所未有的高度。Spark 则是一个专门用来对那些分布式存储的 大数据进行处理的工具,它并不会进行分布式数据的存储。 - 数据处理方式不同
Spark 因为处理数据的方式不一样,会比 Hadoop MapReduce 快上很多。Hadoop MapReduce 是分布对数据进行处理的,先从集群中读取数据,进行一次 处理,将结果写到集群,从集群中读取更新后的数据,再进行下一次的处理,将结果写到集群。
Spark 会在内存中以接近“实时”的时间完成所有的数据分析,集群中读取数据,完成所有必须的分析处理,将结果写回集群,整个计算过程就完成了。
如果需要处理的数据和结果需要大部分情况下是等待的,而且有耐心等待批处理完成的话,Hadoop MapReduce 的处理方式也是完全可以接受的。但如果需要对 流数据进行分析,或者应用需要多重数据处理,更应该使用 Spark 进行处理。
大部分机器学习算法都是需要多重数据处理的。此外,通常会用到 Spark 的应用场景有:实时的市场活动,在线产品推荐,网络安全分析,机器日记监控等。 - 容灾处理
Hadoop 将每次处理后的数据都写入到磁盘中,所以能很有弹性的对系统错误进行处理。Spark 的数据对象存储在分布于数据集群中的叫作 弹性分布式数据集 (RDD,Resilient Distributed Dataset)中。这些数据对象既可以放在内存中,也可以放在磁盘中,所以 RDD 同样也可以提供完整的容灾恢复功能。 - 两者互为互补
Hadoop 提供 HDFS 分布式数据存储功能,还提供了 MapReduce 的数据处理功能、YARN 的资源调度系统。可以使用 Hadoop 自身的 MapReduce 来完成 对数据的处理。
Spark 也并非必须依赖于 Hadoop。由于其没有文件管理系统,必须和其他的分布式文件系统进行集成才能运作。其他选择,例: Red Hat GlusterFS。当 需要外部的资源调度系统来支持时,Spark 可以运行在 YARN 上,也可以运行在 Apache Mesos 上,当然可以用 Standalone 模式。 但 Spark 一般来说还是被用在 Hadoop 上。
Apache Spark 2.0 的新特性
- 更简单:标准的 SQL 以及简化的 API
创建的 API 简单、直观、便于使用:- 标准的 SQl 支持
- 统一 DataFrame/Dataset API
- 更快速:用 Spark 作为编辑器
- 更智能:Structured Streaming(结构化数据流)
只有一次语义,大规模容错,以及高吞吐。
- 集成了 API 与批量作业
- 与存储系统的事物交互
- 可以与 Spark 其他部分丰富的集成
Apache Spark 的安装和使用
相关推荐:
Apache Spark 集群模式
- 组件
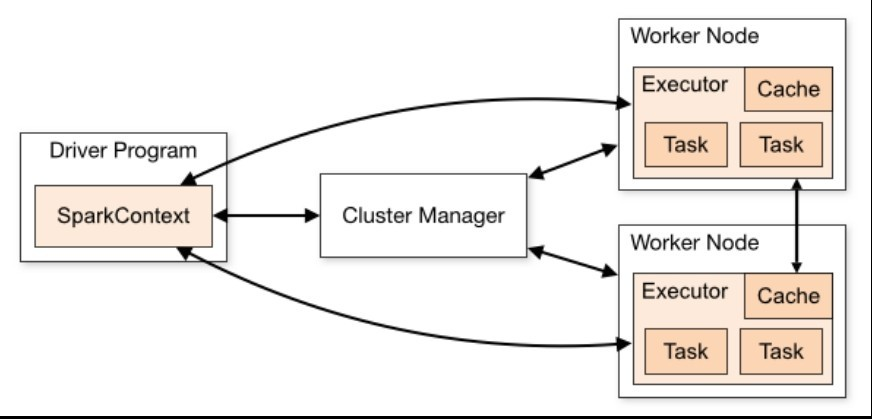
Spark 应用在集群上以独立的进程集合运行,在主程序(driver program)中以 SparkContext 对象来调节。
SparkContext 可以与一个类型的 cluster manager(集群管理器)相连接,包括 Spark 自身的单独集群管理器或者 Mesos、YARN,可以在应用间分配 资源。连接上后,Spark 将获取在集群节点上的 executor(执行器–执行计算和存储应用数据的工作进程)。然后,将应用代码(以 JAR 或者 Python 定义 的文件并传送到 SparkContext)发送到 executor。最后 SparkContext 发送 task(任务)让 executor 运行。
Spark 集群架构图
关于这个架构有几个有用的地方:- 各个应用有自己的 executor 进程,会在整个应用的运行过程中保持并在多个线程中运行 task。好处是在调度方面(各个 driver 调度自己的任务) 和执行方面(不同应的任务在不同的 JVM 上运行)把应用相互孤立起来。然而,这也意味着若不把数据写到额外的存储系统中,数据就无法在不同的 Spark 应用间(SparkContext 的实例)共享
- 潜在的 cluster manager 对于 Spark 来说是透明的。只要能获取到 executor 的进程并通信,那么就能在该 cluster manager 上支持 其他应用(例如,Mesos、YARN)
- driver 在集群上调度 task,运行的位置最好接近工作节点,在相同的局域网内就更好。
- Cluster Manager 类型
目前支持三类 Cluster Manager:- Standalone- -简单的集群管理,其包括一个很容易搭建集群的 Spark
- Apache Mesos- -通用的集群管理,可以运行 Hadoop MapReduce 和服务应用的模式
- Hadoop YARN- -Hadoop2.0 中的资源管理模式
- 提交应用
使用 spark-submit 脚本,可以让应用程序被提交给任何类型的集群。 - 监控器 每个 driver program 都有一个 Web 界面,典型的是在 4040 端口,可以查看有关运行的 task、executor 和存储空间大小等信息。
- 任务调度
Spark 可以通过在应用间(在 cluster manager 水平)和应用里(如果在同一个 SparkContext 中有多个计算指令)进行资源分配 - 常用术语
集群概念中常用的术语术语 含义 Application(应用) 在 Spark 上构建的程序,在集群上由 driver program 和 executor 组成 Application jar 包含了 Spark 应用的 jar 包。用户的 jar 不应该包含 Hadoop 或者是 Spark 的包,而应该在运行时才进行添加 Driver Program(驱动程序) 运行 main() 函数的进程,同时也创建 SparkContext Cluster manager(集群管理器) 在集群上获取资源的扩展服务,比如 standalong 管理器、Mesos、YARN Deploy mode(部署节点) 用来区分 driver 进程的运行位置。在“cluster”模式,框架在集群内部启动 driver,而在“client”模式,提交者在集群外部启动 driver Worker node(工作节点) 任何在集群中可以运行应用的节点 Executor(执行器) 在 worker node 中为应用所启动的进程,可以运行 task 以及可以在内存或硬盘中保存数据。每个应用都有自己的 executor Task(任务) 可以发送给 executor 执行的工作单元 Job(作业) 由多任务组成的并行计算,并能从 Spark action 中获得回应(比如,save、collect); Stage(阶段) 每个 job 被分为很多小的 task 结合,这个进程被称为 stage(和 MapReduce 中的 map 和 reduce 阶段相似)
相关推荐:
Apache Mesos
在传统中,物理机器和虚拟机是数据中心的典型的计算单元。当应用部署后,这些机器需要安装各种配置工具来管理这些应用。机器通常被 组织称集群,提供独立的服务,而系统管理员则监督其日常运作。当这些集群达到其最大容量时,需要多机联网来处理负载。
Apache Mesos 抽象了 CPU、内存、硬盘资源,让数据中心的功能对外就像是一个机器。Mesos 创建一个单独的底层 集群来提供应用程序所需要的资源,而不会超出虚拟机和操作系统的性能限制。
Apache Mesos 简介
有关 Apache Mesos 的介绍,最早可追溯到 Benjamin Hindman 等人所写的技术白皮书 《Mesos: A Platform for fine-Grained Resource Sharing in the Data Center》 。
Mesos 是 Apache 下的开源分布式资源管理框架,被称为分布式系统的内核,使用内置 Linux 内核相同的原理,只是在不同的抽象层次。 该 Mesos 内核运行在每个机器上,在整个数据中心和云环境内向应用程序(例如,Hadoop、Spark、Kafka、Elasticsearch 等)提供资源管理和 资源负载的 API 接口。
Apache Mesos 具有以下特性:
- 线性可扩展性:- -业界认为可扩展到 10000 个节点
- 高可用性:- -使用 ZooKeeper 实现 master 和 agent 的容错,而且实现了无中断的升级
- 支持容器:- -原生支持 Docker 容器和 AppC 镜像
- 可拔插的隔离:- -对 CPU、内存、磁盘、端口、GPU 和模块实现自定义资源的一等(first class)隔离支持
- 二级调度:- -支持在相同集群中使用可插拔调度策略来运行云原生和遗留的应用程序
- API:- -提供 HTTP API 在操作集群、监控等方面开发新的分布式应用程序
- Web 界面:- -内置 Web 界面查看集群的状态,并可以导航 container sandbox(容器沙箱)
- 跨平台:- -可以在 Linux、OSX 和 Windows 上运行,并且与云服务提供商无关
Mesos 框架
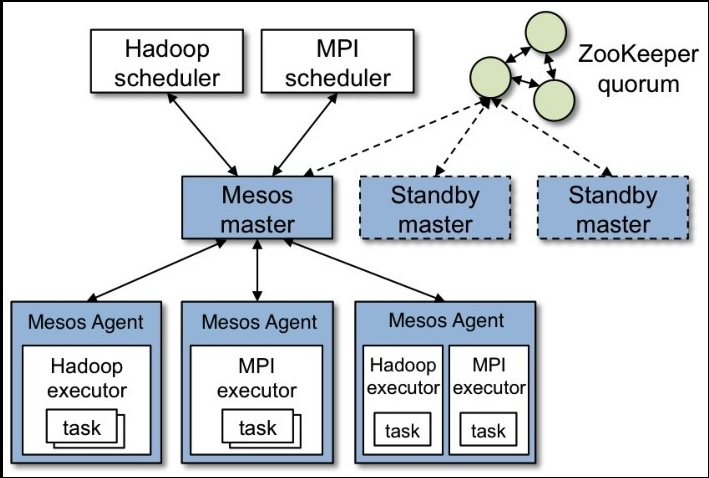
- Mesos 主要由 master 守护线程和 Mesos framework 组成。master 守护线程用于管理运行在每个集群节点的 agent 守护线程。 Mesos framework 用来运行 agent 上的 task。
- master 通过 framework 来使资源成为 resource offer,这样就能使用细颗粒度的资源共享(CPU、RAM等)。每个 resource offer 包含了 <agent ID,resource1: amount1, resource2: amount2…>列表。master 根据给定的组织策略来决定多少资源能够提供给每个 framework, 其中策略有 fair sharing(公平共享)或 strict priority(严格优先级)。为了支持策略的多样化,master 采用了模块化架构,可以很容易 的通过一个插件机制来增加新的分配模块。
- framework 运行在 Mesos 的顶层,主要由两个组件组成:scheduler 和 executor。scheduler 注册到 master 来分配资源,而 executor 进程则启动 agent 节点来运行 framework 任务。同时,master 决定分配多少资源提供给 framework,scheduler 决定使用哪些提供的资源。 当 framework 接收了提供的资源,会传递给 Mesos 一个描述符,告知 Mesos 想启动哪个 task。接着,Mesos 启动对应 agent 的 task。
Apache Mesos 的安装、使用
相关推荐:
设计高可用的 Mesos framework
Mesos framework 用于管理 task。为了使 Mesos framework 高可用,必须持续在各种故障场景中正确管理 task。需要考虑一下常见的故障条件:
- framework scheduler 所连接的 Mesos master 出现故障,例如,崩溃或失去了网络连接。如果 master 配置为 high-availability mode( 高可用性模式),这将推动另一个 Mesos master 副本成为当前的 leader。这种情况下,scheduler 应与新的 master 重新注册,并确保 task 的 状态是一致的。
- framework scheduler 所运行的主机出现故障。为了确保该 framework 仍然可用,并能继续安排新的 task,framework 应确保在不同的节点上运行 scheduler 的多个副本,并且在前任 leader 失败后,该备份副本能晋升为当前新的 leader。Mesos 本身没有规定 framework 应该如何处理这种情况。 一种不错的方式: 部署多个 使用长时间运行的 task 的 framework scheduler 的副本,如 Apache Aurora 或 Marathon
- task 所运行的主机出现故障。可替代的,节点本身可能没有故障,但该节点上的 Mesos agent 可能无法与 Mesos master 通信。例如,由于进行了网络 分区导致无法通信。
分布式存储
Bigtable
Bigtable 是非关系型数据库,是一个稀疏的、分布式的、持久化存储的多维度排序 map。设计目的是快速且可靠的处理 PB 级别的 数据,并且能够部署到上千台机器上。
Bigtable 已经实现了的目标:适用性广泛、可扩展、高性能和高可用性。
Bigtable 简介
有关 Bigtable 的描述,最早可见 Google 发表于 2006 年在 OSDI 上的论文《Bigtable: A Distributed Storage System for Structured Data》
Bigtable 将存储的数据都视为字符串,但是 Bigtable 自身不去解析这些字符串,客户程序通常会把各种结构化或者半结构化的数据串行化到这些字符串。
Bigtable 技术本身是闭源的,Cloud Bigtable 是 Google 提供的大数据存储云服务。业界的 Bigtable 模型的开源实现有 Apache HBase
Bigtable 具备如下特点:
- 适合大规模海量数据(PB 级数据)
- 分布式、并发数据处理,效率极高
- 易于扩展,支持动态伸缩
- 适用于廉价计算机服务
Bigtable 的局限性:
- 适合于读操作,不适合写操作
- 不适用于传统关系型数据库
Bigtable 的数据模型
Bigtable 是一个稀疏的、分布式的、持久化存储的多维度排序map。map的索引是由 row key(行键)、column key(列键)以及 timestamp(时间戳) 来确定的;map 中的每个 value 都是一个未经解析的 byte 数组。映射关系如下:
(row: string, column: string, time: int64)->string
- Row(行)
表中的 row key 可以是任意的字符串(目前支持最大 64KB 的字符串,对大多数用户,10~100字节就足够了)。对同一个 row key 的读或者写操作 都是原子的,这个设计决策能够使用户很容易的理解程序在对同一个 row 进行并发更新操作时的行为。 - Column Family(列族)
column key 组成的集合叫作“column family(列族)”,column family 是访问控制的基本单位。同一 column family 下的所有数据通常都属于 同一个类型。column family 在使用之前必须先创建,然后才能在 column family 中任何的 column key 下存放数据;column family 创建后, 其中的任何一个 column key 下都可以存放数据。column key 的命名语法如下:family: qualifier。column family 的名字必须是可打印的字 符串,而限定符的名字可以是任意的字符串。
访问控制、磁盘和内存的使用统计都是在 column family 层面进行的。 - Timestamp(时间戳)
表的每一个数据项都可以包含同一份数据的不同版本,不同版本的数据通过 Timestamp 来索引。Bigtable 的 timestamp 类型时 64 位整型。数据项中, 不同版本的数据按照 timestamp 倒序排序,即最新的数据排在最前面。
为了减轻多个版本数据的管理负担,每一个 column family 都配有两个设置参数,Bigtable 通过这两个参数可以对废弃版本的数据自动进行垃圾收集。
Bigtable 的实现
Bigtable 包括了三个主要的组件: 连接到客户程序中的库、一个 master 服务器和多个 tablet 服务器。针对系统工作负载的变化情况,Bigtable 可以动态的向集群中添加或者删除 tablet 服务器。
master 服务器主要负责的工作: 为 tablet 服务器分配 tablet,检测新加入的或者过期失效的 tablet 服务器,对 tablet 服务器进行负载均衡、 以及对保存在 GFS 上的文件进行垃圾收集 。除此之外,还处理对模式的相关修改操作。
每个 tablet 服务器都管理一个 tablet 的集合(通常每个服务器有大约数十个至上千个 tablet)。负责处理所加载的 tablet 的读写操作,以及 tablet 过大时,对其进行分割,root tablet 不会被分割。默认的情况下,每个 tablet 的尺寸大小约是 100MB 到 200MB。
-
tablet 的位置信息
tablet 的位置信息是使用一个三层的、类似 B+ 树的结构存储。
第一层是一个存储在 Chubby 中的文件,包含了 root tablet 的位置信息。Chubby 是 Google 设计的一种 分布式系统的锁服务 ,其目的是提供
粗粒的锁定以及可靠的存储。可参考 Mike Burrows 的论文【The Chubby lock service for loosely-coupled distributed systems】 -
tablet 分配
任何时刻,一个 tablet 只能分配给一个 tablet 服务器。Bigtable 使用 Chubby 来跟踪记录 tablet 服务器的状态。当一个 tablet 服务器启动时, 它在 Chubby 的一个指定目录下建立一个唯一性名字的文件,并且获取该文件的独占锁。master 服务器实时监控这个目录(服务器目录),因此 master 服 务器能够知道有新的 tablet 服务器加入。master 服务器通过轮询 tablet 服务器文件锁的状态来检测何时 tablet 服务器不再为 tablet 提供服务。 -
tablet 服务
tablet 的持久化状态信息保存在 GFS 上。更新操作提交到 redo 日志中。在这些更新操作中,最近提交的存放在一个排序的缓存(memtable)中,较早 的更新存放在一系列 SSTable 中。
当对 tablet 服务器进行读操作时,tablet 服务器会进行类似的完整性和权限检查。一个有效的读操作在一个由一些列 SSTable 和 memtable 合并的 视图里执行。由于 SSTable 和 memtable 是按字典排序的数据结构,因此可以高效生成合并视图。
当进行 tablet 的合并和分割时,正在执行的读写操作能够继续进行。 -
Compaction(合并)
随着写操作的执行,memtable 的大小不断增加。当 memtable 的大小到达一个限制的时候,这个 memtable 就会被冻结,然后创建一个新的 memtable; 被冻结住的 memtable 会被转换成 SSTable,然后写入 GFS。称这种 compaction 行为为 minor compaction。minor compaction 过程有两个 目的: 减少 tablet 服务器所需要使用的内存,以及在服务器容灾恢复过程中,减少必须从提交日志里读取的数据量。 在 Compaction 过程中,正在进 行的读写操作仍能继续。
通过定期在后台执行 merging compaction 过程合并文件,限制 SSTable 的数量。
合并所有的 SSTable 并生成一个新的 SSTable 的 merging compaction 过程叫作 major compaction。该机制允许 Bigtable 回收已经删除数据 占有的资源,并且确保 BigTable 能及时清除已经删除的数据,这对存放敏感数据的服务是非常重要的。
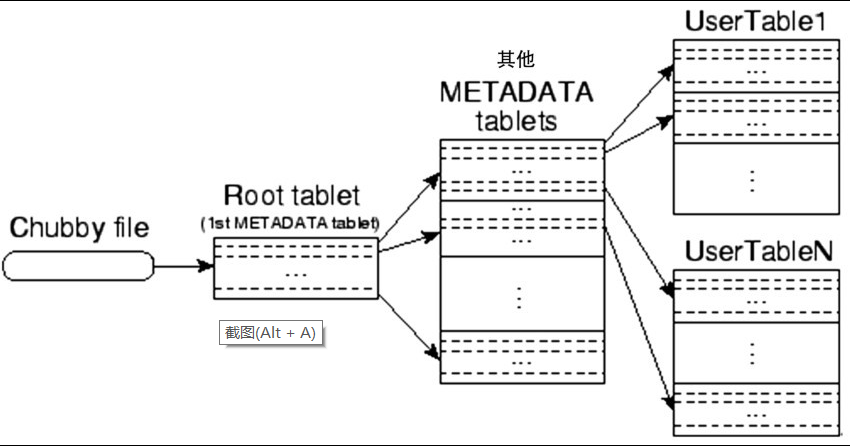 第一层是一个存储在 Chubby 中的文件,包含了 root tablet 的位置信息。Chubby 是 Google 设计的一种 分布式系统的锁服务 ,其目的是提供
粗粒的锁定以及可靠的存储。可参考 Mike Burrows 的论文
第一层是一个存储在 Chubby 中的文件,包含了 root tablet 的位置信息。Chubby 是 Google 设计的一种 分布式系统的锁服务 ,其目的是提供
粗粒的锁定以及可靠的存储。可参考 Mike Burrows 的论文Bigtable 的性能优化
- Locality Group(本地组)
客户程序可以将多个 column family 组合成一个 locality group。 - 压缩
客户程序可以控制一个 locality group 的 SSTable 是否需要压缩,以及当需要压缩时,以什么格式来压缩。很多客户程序使用了“两遍”的、可定制的压缩 方式。第一遍采用 Long Common Strings 的方式,这种方式在一个很大的扫描窗口里对常见的长字符串进行压缩,有关这种方式,可以参见 Jon Bentley 和 Douglas McIlroy 发表的论文《Data Compression Using Long Common Strings》。第 二遍是快速压缩算法,即在一个 16KB 的小扫描窗口寻找重复数据。 - 缓存
为了提供读操作的性能,tablet 服务器使用二级缓存的策略。Scan Cache 是第一级缓存,主要缓存 tablet 服务器通过 SSTable 接口获取的 key-value 对;Block Cache 是二级缓存,缓存的是从 GFS 读取的 SSTable 的数据块。 - Bloom 过滤器
一个读操作必须读取构成 tablet 状态的所有 SSTable 的数据。通过允许客户程序对特定 locality group 的 SSTable 指定 Bloom过滤器,来减少磁盘 访问的次数。 - Commit 日志的实现 对每个 tablet 的操作的 commit 日志都存在一个单独的文件,就会产生大量的文件,并且这些文件会并行写入 GFS。为了避免这些问题,设置 tablet 服务 器一个 commit 日志文件,把修改操作的日志以追加方式写入同一个日志文件。
- 加快 tablet 修复
当 master 服务器将一个 tablet 从一个 tablet 服务器移到另一个 tablet 服务器时,源 tablet 服务器就会对这个 tablet 做一次 minor compaction。这能减少 tabelt 服务器的日志文件中没有合并的记录,从而减少恢复的时间。 - 利用不变性
在使用 Bigtable 时,除了 SSTable 缓存,其他部分产生的 SSTable 都是不变的,可以利用这点对系统进行简化。
因为不变性使得分割 tablet 的操作非常快捷。
Apache HBase
Apache HBase 是一个分布式的、面向列的开源数据库。Apache HBase 在 Hadoop 之上提供了类似 Bigtable 的能力。HBase 不 同一般的关系数据库,是一个适合于非结构化数据存储的数据库,并且是基于列而不是基于行的模式。
Apache HBase 简介
Apache HBase(Hadoop Database)是一个 高可靠性的、高性能、面向列、可伸缩 的分布式存储系统。
HBase 利用 Hadoop HDFS 作为其文件存储系统;利用 Hadoop MapReduce 来处理 HBase 中的哈力量数据;利用 ZooKeeper 作为协同服务。
HBase 是一种“NoSQL”数据库。从技术上来说,HBase 更像是“Data Store(数据存储)”多于“Data Base(数据库)”。
HBase 具有以下特性:
- 强一致性读写:HBase 不是“Eventual Consistency(最终一致性)”数据存储,使其适合高速计算数聚合类任务
- 自动分片(Automatic sharding):HBase 表通过 region 分布在集群中,数据增长时,region 会自动分割并重新分布
- RegionServer 自动故障转移
- Hadoop/HDFS 集成:HBase 支持开箱即用的 HDFS 作为它的分布式文件系统
- MapReduce:HBase 通过 MapReduce 支持大并发处理
- Java 客户端 API:HBase 支持易于使用的 Java API 进行编程访问
- Thrift/REST API:HBase 也支持 Thrift 和 REST 作为非 Java 前端的访问
- Block Cache 和 Bloom Filter:对于大容量查询优化,HBase 支持 Block Cache 和 Bloom Filter
- 运维管理:HBase 支持 JMX 提供内置网页用于运维
HBase 的应用场景
- 确保有足够多数据,有上亿或上千亿行数据,HBase 是很好的备选。只有上千或上百万行,用传统的 RDBMS 可能是更好的选择。
- 确保可以不依赖所有 RDBMS 的额外特性。
- 确保有足够的硬件。
HBase 不适合所有场景
HBase 的优缺点
- HBase 的优点
- 列可以动态增加,并且列为空不存储数据,节省存储空间
- 可以自动切分数据,是的数据存储自动具有水平扩展功能
- 可以提供高并发读写操作的支持
- 与 Hadoop MapReduce 相结合有利于数据分析
- 容错性
- 版权免费
- 非常灵活的模式设计(或者说没有固定模式的限制)
- 可以跟 Hive 集成,使用类 SQL 查询
- 自动故障转移
- 客户端接口易于使用
- 行级别原子性,即 PUT 操作一定是完全成功或者完全失败
- HBase 的缺点
- 不能支持条件查询,只支持按照 row key 来查询
- 容易产生单点故障(只使用一个 HMaster 的时候)
- 不支持事务
- JOIN 不是数据库层支持的,而需要用 MapReduce
- 只能在主键上索引和排序
- 没有内置的身份和权限认证
HBase 与 Hadoop/HDFS 的差异
HDFS 是分布式文件系统,适合保存大文件。HBase 基于 HDFS,并能够提供大表的记录快速查找和更新。HBase 内部将数据放到索引好的“StoreFiles”存储
文件中,以便提供高速查询,而存储文件位于 HDFS 中。
相关推荐:
- 《Learning HBase》
- 《HBase: The Definitive Guide》
Apache HBase 基本概念
在 HBase 的数据被存储在表中,具有行和列。
- 术语
- Table(表):由多个 row 组成
- Row(行):每个 row 代表一个数据对象,每个 row 都是以一个 row key(行键)和一个或多个 column 组成的。row key 是每个数据对象的唯一 表示的,按字母顺序排序,即 row 也是按照这个顺序来进行存储的。所以,row key 的实际相当重要,重要的原则是: 相关的 row 要存储在接近的位置。
- Column(列):由 column family 和 column qualifier 组成,由冒号(:)进行间隔
- Column Family(列族): 是一些 column 的集合。column family 所有成员有相同的前缀。冒号(:)是 column family 的分隔符,用来 区分前缀和列名。前缀必须是可打印的字符,剩下的部分列名可以是任意字节数组。
- Column Qualifire(列限定符):column family 中的数据通过 column qualifier 来进行映射。
- Cell(单元格):是 row、column family 和 column qualifier 的组合,包含了一个值和一个 timestamp,用于标识值的版本
- TimeStamp(时间戳):每个值都会有一个 timestamp,作为该值特定版本的标识符。默认情况下,timestamp 代表了当数据被写入 RegionServer 的时间,但也可以在把数据放到 cell 时指定不同的 timestamp。
- map
**HBase/Bigtable 的核心数据结构就是 map。**不同的编程语言针对 map 有不同的术语,比如 associative array(PHP)、associative array (Python)、Hash(Ruby)或 Object(JavaScript)。 - 分布式
- 排序
HBase/Bigtable 中的 map 是按字母顺序严格排序的。在一个大数据量的系统里面,排序很重要,特别是 row key 的设置策略决定了查询的性能。 - 多维
多维 map,即 map 里面嵌套 map。 - 时间版本
在查询中不指定时间,返回的将是最近的一个时间版本。 - 概念视图
- 物理视图
- 数据模型操作
四个主要的数据模型操作是 Get、Put、Scan 和 Delete,通过 Table 实例进行操作。Table 相关的 API- Get–返回特定 row 的属性。通过 Table.Get 执行。Get 相关的 API
- Put–向 table 增加新 row(如果 key 是新的)或更新 row(如果 key 已经存在)。Put 通过 Table.Put(WriteBuffer)或 Table.batch (非writeBuffer)执行。Put 相关的 APi
- Scan–允许多个 row 特定属性迭代。Scan 相关的 API
- Delete–用于从 table 中删除 row。通过 Table.delete 来执行操作。Delete 相关的 API
- Namespace(命名空间)
- 指对一组 table 的逻辑分组,类似 RDBMS 中的 database,方便对 table 在业务上进行划分。这种抽象奠定了 multi-tenancy(多租户)相关功能:
- Quota Management(配额管理)–限制 namespace(比如,region、table)的使用
- Namespace Security Administration(命名空间安全管理)–提供租户另一个层次的安全管理
- Region 服务器组–命名 namespace/table 可以固定到某个 RegionServer 的子集,从而保证了隔离。
- namespace 管理: 可以被创建、删除、修改。table 和 namespace 的隶属关系在创建 table 时决定,通过以下格式来指定:
1
<table namespace>:<table qualifier>
- 预定义的 namespace
- Hbase- -系统 namespace,用于包括 HBase 内置表
- default- -用户建表时未指定 namespace 的 table 都默认使用该 namespace
Apache HBase 架构
MapR 公司的架构师 Carol McDonald 有非常深入的讲解《An In-Depth Look at the HBase Architecture》。 在物理上,HBase 遵循的是 master-slave 模式,由三种类型的服务器组成。其中,Region 服务器提供数据的读写;Region 的分配、DDL 操作(创建、 删除 table)由 HBase Master(HMaster)线程处理;ZooKeeper 作为 HDFS 的一部分,用于维护现场集群的状态。
Hadoop DataNode 存储 Region Server 在管理过程中的数据。所有 HBase 的数据存储在 HDFS 文件中。
NameNode 会维护所有组成该文件的物理数据块的元数据信息。
- Region
待整理
相关推荐:
Apache Cassandra
待整理
Memcached
Memcached 是一个高性能的分布式 内存 对象缓存系统,用于动态 Web 应用以减轻数据库负载。通过在内存中缓存 数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。基于一个存储 key-value 对的 hashmap。
Memcached 简介
Memcached 是免费、开源、高性能、分布式的内存对象缓存系统,通用性强,主要用于减少数据负载,加快动态 Web 应用程序。
Memcached 是基于内存的 key-value 模型,可以用于存储来自数据库调用、API 调用或网页渲染后的任意小块数据(字符串、对象)。
Memcached 是简单而强大的。简单的设计加强了快速部署,易于开发,解决了大量数据高速缓存的很多问题。
Memcached 作为高速运行的分布式缓存服务器,具有以下特点:
- 协议简单
- 基于 libevent 的事件处理
- 内置内存存储方式
- Memcached 不互相通信
Memcached 主要由以下部分组成:
- 客户端软件:能够获取到可用的 Memcached 服务器的列表
- 基于客户端的散列算法:会根据“key”来选择服务器
- 服务器软件:存储 key-value 到内部哈希表
- LRU:Least Recently Used(最近最少使用算法)来决定何时要清除掉旧数据(如果内存不足的话),或重复使用内存。
Memcached 的架构
Memcached 拥有非常精简的架构设计理念,可以按需来更好的利用内存。
Memcached 主要包括以下核心设计理念
- 简单的 key-value 存储 数据由一个 key、过期时间、可选的标志以及原始数据组成。可以使用某些命令(incr/decr)对基础数据进行简单的操作
- 逻辑一半在客户端,一半在服务器
- 服务器之间是无连接的
由客户端来直接删除或覆盖其在服务器上所用的数据 - O(1)
所有的命令都被设计为尽可能 快和对锁友好。提高了所有用例的确定性查询的速度。 - “遗忘“功能
默认采用 LRU 的缓存机制,数据会在指定时间后过期。即限制了陈旧未使用的数据,也能保证进场被使用的数据可以被缓存。
垃圾回收器无需“pauses(暂停)”等待,确保低延迟和懒加载空闲的空间。 - 缓存失效
无需广播服务器的变化到所有可用的主机上,作为替代者,客户端可以直接解决服务器上已保存的数据失效问题。
Memcached 的安装、使用
相关推荐:
Memcached 客户端
- telnet
telnet 可以通过命令行的方式来监控 Memcached 服务器存储数据的情况
相关推荐:
Redis
Redis 是一个 key-value 模型的内存数据存储系统。和 Memcached 类似,支持存储的 value 类型更多,包括支持 string(字符串),hash(哈希类型)、list(链表)、set(集合)和 sorted set(有序集合)的 range query(范围查询),以及位图、 hyperloglogs、空间索引等。radius query(半径查询)。内置复制、Lua脚本、LRU回收、事务以及不同级别磁盘持久化功能,同时通过 Redis Sentinel 提供高可用,通过 Redis Cluster 提供自动分区。Redis 是完全开源免费的、遵守 BSD 的协议。
Redis 简介
Redis 是一个高性能的 key-value 数据库。支持主从同步。完全实现 发布/订阅 机制,使得从数据库在任何地方进行数据同步时,可订阅一个频道并 接收主服务器完整的消息发布记录。同步 对读取操作的可扩展性和数据冗余很有帮助。
可以在 Redis 数据类型上执行原子操作。为了获取其卓越的性能,Redis 可以在存储数据集合上工作。
Redis 具有以下的特点:
- 事务
- 发布/订阅
- Lua 脚本
- key 有声明时间限制
- 按照 LRU 机制来清除旧数据
- 自动故障转移
Redis 的下载、安装、使用
1 | # install redis on centos |
相关推荐:
Redis 的数据类型及抽象
Redis 不仅是 key-value 存储,也是 data structure server(数据结构服务器),用来支持不同的数值类型。value可以是不同的数据结构:
- 二进制安全的 string
- List–表,表中的元素按照插入顺序排列
- Set–String 集合,集合中的元素是唯一的,随机排列
- Sorted set–和 set 类似,但是每个 string 元素关联一个浮点数值(Score)。元素总是通过 score 来进行排序,所以可以获取一段范围的元素。
- Hash–Hash 就是由关联值的字段构成的 Map。字段和值都是 string。与 python 的 hash 类似
- Bit array(简称 Bitmap)–位图
- HyperLogLogs–概率统计用的数据结构,可以被用来估计一个集合的技术。
MongoDB
MongoDB 是一个 介于关系数据库和非关系数据库 之间的产品。是非关系数据中功能最丰富的、最像关系数据库的。支持的结构非常松散, 是类似 JSON 的 BSON 格式,可以存储比较复杂的数据类型。支持的查询语言非常强大,语法有点 类似于面向对象的查询 语言。
MongoDB 简介
MongoDB 是面向文档的数据库(Document Database),特点是高性能、高可用性,以及可以实现自动化扩展,存储数据非常方便。
主要功能特性:
- 将数据存储为一个文档,数据结构由 field-value(字段-值)对组成
- 文档类似于 JSON 对象,字段的值可以包含其他文档、数组及文档数组
使用文档的优点:- 文档(即对象)在许多编程语言里,可以对应于原生数据类型
- 嵌入式文档和数组可以减少昂贵的连接操作
- 动态模式支持流畅的多态性
优点:
- 高性能
MongoDB 提供高性能的数据持久化。- 对于嵌入式数据模型的支持,减少了数据库系统的 I/O
- 支持索引。索引对象可以是嵌入文档或数组的key
- 丰富的查询语言
包括读取和写入操作(CRUD)以及 数据聚合、文本搜索和地理空间查询 - 高可用
复制设备被称为 replica set,提供的功能: 自动故障转移、数据冗余
replica set 是一组保存相同数据集合的 MongoDB 服务器,提供了数据冗余并提高了数据的可用性。 - 横向扩展
提供横向扩展并作为核心功能:
- 将数据分片到一组计算机集群上
- tag aware sharding(标签意识分片)允许将数据传到特定的碎片
- 支持多个存储引擎
- WiredTiger Storage Engine
- MMAPV1 Storage Engine
提供插件式存储引擎的 API,允许第三方开发
MongoDB 的安装、配置、运行
相关推荐:
MongoDB 核心概念
- 数据库和集合
存储 BSON 文档(数据记录)在集合(collection)中,集合是在数据库(database)中。1
2
3use db_name # 使用数据库,不存在则创建库
db.myNewCollection.insert({x:1}) # 向集合 myNewCollection 插入数据,若不存在集合则创建
db.createCollection() # 显示创建带有各种选项的集合,比如设置最大尺寸或文档验证规则。 - Capped Collection(限制集合)
限制集合是固定大小的结合,用于支持基于文档插入顺序的高吞吐率的插入和检索操作。工作原理在某种程度上类似于 circular buffer(循环缓冲区): 当 文档填满分配到的空间后,将通过在 Capped Collection 中重写老文档来腾出空间。createCollection create- 插入顺序
Capped Collection 能够保留插入顺序。查询是按照文档的插入顺序而不是使用索引来确定插入位置的,可以提高增添数据的效率,所以可以支持 更高的插入吞吐 - 最旧文档的自动删除
- _id 索引
- 更新
- 文档大小
MongoDB3.2 版本之后,如果一个更新或替换操作改变了文档大小,操作会失败。 - 文档删除
不能从一个 Capped Collection 中删除文档,为了从一个集合中删除所有文档,使用drop()方法来删除集合然后重新创建 Capped Collection - 分片(Sharding)
不能对 Capped Collection 进行分片 - 查询效率
用自然顺序检索集合中大部分最近插入的元素。类似于查询日志文件的尾部内容 - 聚合 $out
聚合管道操作器 $out 不能将结果写入 Capped Collection - 创建 Capped Collection
必须使用db.createCollection()方法显示创建 Capped Collection,在 mongo shell 的 create 命令中可以查看帮助信息。当创建 Capped Collection 时,必须指定以字节为单位的最大集合大小,MongoDB 将预先分配集合。Capped Collection 的大小包括内部消耗的一小部分 空间。如果 size 字段小于或等于 4096,该集合将会有 4096 个字节,否则的话,MongoDB 将会在给定大小的基础上增加为 256 的倍数 另外,可以指定集合最大文档数量,使用 max 字段1
db.createCollection("log", {capped: true, size: 10000})
size 参数是必须的,即使指定了文件的 max 数量。如果集合达到最大数量的限制,在没有达到最大文档计数之前,MongoDB 将删除旧文档。1
db.createCollection("log", {capped: true, size: 5242880, max: 5000})
- 查询 Capped Collection
1
2db.cappedCollection.find() # 获取结果与插入顺序相同
db.cappedCollection.find().sort( { $natural: -1}) # 获取结果与插入顺序相反,将 $natural 参数设置为 -1 - 检查一个集合是否是 Capped Collection
1
db.collection.isCapped()
- 将集合转换为 Capped Collection此命令将获得一个全局写锁并阻塞其他操作
1
db.runCommand({"convertToCapped": "my_coll", size: 10000});
- 在规定的时间周期之后自动移除数据 当需要设置数据过期时,可以考虑使用 MongoDB 的 TTL 索引。TTL Collections 与 Capped Collection 不兼容
- Tailable Cursor(结尾光标)
同 UNIX 的tail -f命令相似
- 插入顺序
- Document(文档)
BSON 是 JSON 文档的二进制表示,但拥有比 JSON 更多的数据类型,BSON 规范- 文档结构
由 field value(字段/值)对组成,字段的值可以是任意 BSON 数据类型,包括其他文档、数组及文档数组。 - 字段名称
字段名称是字符串。文档中对于字段名称有如下限制:- 字段名称 _id 被保留为主键,并可以是出 array 以外的任何类型
- 该字段名称不能以美元符号 $ 字符开头
- 字段名称不能包含点 . 字符
- 字段名称不能包含空(null)字符
BSON 文档可能有多个字段具有相同名称。大多数的 MongoDB 接口用来代表一个 MongoDB 结构(如,hash table),不支持重复的字段名称。如果需要
相同名称的多个字段的文档,参阅 MongoDB 驱动程序相关内容。
内部 MongoDB 的进程创建的一些文件可能有重复的字段,但是进程不会不断增加重复字段到现有用户的文档中。
- 字段值限制
索引的集合,其值收到字段值 Maximum Index Key Length 的限制,参阅
- 文档结构
MongoDB 的数据模型
数据建模简介
MongoDB 的集合不强制文档的结构,以便能灵活的映射文件到一个实体或对象。每个文档可以匹配所要表示实体的数据字段。实际操作中,一个集合的文档共享 一个相似的结构。
数据模型的关键在于平衡应用的需要、数据库引擎的性能和数据存取模式。
- 文档结构
关键是围绕文档的结构和应用如何表示数据间的联系。有两个工具允许应用表示:引用和嵌入文档 - 引用(Reference)
通过文档之间的链接 link 或 reference 来存储数据间的关系。应用能解析引用来访问相关数据。广义上,都是 normalized data model(规范化的数 据模型),数据模型使用引用来联系文档。
normalized data model 一般的使用情况:- 当嵌入会导致数据重复且不具备有效的读性能优势时
- 需表示更复杂的多对多的关系时
- 对大型分级数据建模引用比嵌入式文档的灵活性更大时 由于使用 normalized data model 需要更多的往返服务器,客户端应用必须处理应用带来的查询问题。
- 嵌入式数据(Embedded Data)
通过在一个单一文档结构里存储相关数据来捕获数据间的关系。能够实现在一个文档里的一个字段或字段数据里嵌入一个文档作为子文档。这些非规范化数据 使得应用可以在一个单一数据库操作里获取和操作数据。
嵌入式文档的模型数据优缺点:- 可以在一个单一结构或文档中嵌入相关数据,这个模型是著名的 “非规范化”模型
- 允许应用在相同的数据库记录里存储相关片段信息。完成常规操作时,只需处理很少的查询或更新。 嵌入式数据模型一般的使用情况:
- 实体间有“包含关系”或者实体键有一对多的关系。
- 写操作的原子性
写操作在文档这一级是原子性的 - 文档增长
有的更新,比如向数组添加元素或添加新的字段,会增大文档的大小。文档的增长会影响规范化和非规范化数据的选择。 - 数据使用和性能
数据模型的例子和模式
- 嵌入式文档的一对一关系
- 嵌入式文档的一对多关系
- 引用文档的一对多关系
- 父引用的树结构 存储每个树节点在文档中;除了树节点,文档还存储节点的父节点的 id。缺点:需要多次查询检索子树
- 自引用的树结构
存储每个树节点在文档中;除了树节点,文档还存储了节点的子节点的 id 数组。 - Array of Ancestors (祖先数组)的树结构
存储每个树节点在文档中;除了 ancestors 字段,还存储父“类别”到字段 parent 里面
相关推荐:
- 【】
分布式监控
Nagios
Nagios 简介
Nagios Core 主要提供如下功能:
- 监控网络服务(SMTP、POP3、HTTP、NNTP、PING 等)
- 监控主机资源(处理器负荷、磁盘利用率等)
- 简单的插件设计使得用户可以方便的扩展自己服务的检测方法
- 并行服务检测机制
- 具备定义网络分层结构的能力,用“parent”主机定义来表达网络主机间的关系,这种关系可被用来发现和明细主机宕机或不可达状态
- 服务器或主机产生问题以及问题解决时将告警发送给联系人(E-mail、短信或者用户自定义方式)
- 具备定义事件句柄功能,可以在主机或服务的时间发生时获取更多问题定位
- 自动的日志文件回滚
- 可以支持并实现对主机的冗余监控
- 可选的 Web 界面用于查看当前的网络状态、通知和故障历史、日志文件等 Nagios Core 的开源协议是 GNU General Public License Version 2
Nagios 的安装、使用
Zabbix
Zabbix 简介
Zabbix 是一个企业级的、开源的、分布式的监控套件。Zabbix 可以监控服务器、虚拟机和网络设备的运行状况。提供了数据采集强大的 性能和可扩展性,支持代理。
Zabbix 是一个高度集成的网络监控套件,有如下特性:
- 数据收集
- 可用性及性能检测
- 支持 SNMP(trapping 及 polling)、IPMI、JMX、VMware 等的监控
- 自定义检测
- 自定义间隔来收集数据
- 通过 server/proxy 和 agent 来执行
- 灵活的阈值定义
- 允许灵活的自定义阈值,在 Zabbix 中称为触发器(Trigger)
- 高级告警配置
- 可以发送自定义的升级计划、接收者及媒体类型的通知
- 通知信息可以配置并允许使用宏(macro)变量
- 通过远程命令等实现自动化动作
- Web 监控功能
- Zabbix 可以按照在网站上模拟鼠标点击的路径来检查功能和响应时间
- 实时绘图
- 通过内置的绘图方法实现监控数据实时绘图
- 扩展的图形化显示
- 允许自定义创建多监控项的视图
- 网络拓扑(network maps)
- 自定义的面板和界面,并允许在控制面板页面显示
- 报告
- 高等级(商业)监控资源
- 历史数据存储
- 数据存储在数据库中
- 历史数据可配置
- 内置数据清理机制
- 配置简单
- 通过添加监控设备方式来添加主机
- 只需配置一次在数据库中,就能长期监控
- 监控设备允许使用模板
- 模板使用
- 模板中可以添加组监控
- 模板允许继承
- 网络自动发现
- 自动发现网络设备
- agent 自动注册
- 自动发现文件系统、网卡设备、SNMP OID 等
- 快速的 Web 界面
- Web 前端采用 PHP 编写
- 访问无障碍
- 审计日志
- Zabbix API
- 提供程序级别的访问接口
- 权限系统
- 安全的权限认证
- 可以限制允许维护的列表
- 全特性、agent 易扩展
- 在被监控目标上进行部署
- 支持 Linux 及 Windows
- 二进制守护进程
- C 语言开发,高性能,低内存消耗
- 易移植
- 具备应对复杂环境情况的能力
- 通过 Zabbix proxy 可以非常容易的创建远程监控
安装 Zabbix
Zabbix 对于容器的支持
Zabbix 基本概念
基本术语
- host(主机)–被监控的网络设备(需要IP/DNS)
- host group(主机组)–逻辑的主机组,包含 host 和 template。在同一个主机组里面的 host 和 template 不能互相被连接。host group 通常用 于给不同的用户组创建访问权限。
- item(监控项)–从主机中收集到的数据特定部分
- trigger(触发器)–一个逻辑表达式,用来表达从监控项获取的数据达到了预设的问题阈值。当接收到监控值达到了预设的阈值,则触发器状态由“OK”变更为 “Problem”;当收到的监控值低于阈值,则状态保持/变更为“OK”。
- media(媒介)–发送通知的渠道
- notification(通知)–通过 media 渠道发送时间的消息
- remote command(远程命令)–当监控主机达到某些条件后预设的自动执行的命令
- template(模板)–一组包含 item、trigger、绘图、面板(screen)、application、低级别自动发现规则、web scenario 等并且能被其他主机应 用的实体。模板能够提升主机部署监控任务的速度,同时也非常容易对监控任务做批量更新。模板可以被直接连接到单独主机。
- application(应用)–item 的逻辑分组
- web scenario(Web 方案)–对一个 Web 站点的可用性进行检查的一个或多个 HTTP 请求
- frontend(前端)–Zabbix 提供的 Web 界面
- Zabbix API–Zabbix API 允许通过 JSON RPC 协议去创建、更新、获得 Zabbix 对象(如 host、item、绘图等)以及完成自定义任务
- Zabbix server–Zabbix 软件中心进程,用于连通 Zabbix proxy 及 agent 完成监控、计算 trigger、发送 notification 以及承担数据的集中 存储的功能
- Zabbix agent–部署在监控主机上的进程,用于监控本地资源和应用
- Zabbix proxy–替代 Zabbix server 完成数据收集的进程,通常用于降低中心 Zabbix server 的负载
Server
执行 polling(轮询) 和 trapping(捕获) 来采集数据,评估是否出发触发器,发送通知给用户。是 agent 和 proxy 报告系统可用性和完整性数据的 中心组建。也可以通过简单服务检查来完成远程网络服务检测,比如 Web 服务器、邮件服务器。
Server 是所有配置、统计和操作数据的中心存储仓库,也是在所有的监控系统中扮演故障发生时通知管理员的角色。
基础的 Zabbix sever 依据功能不同划分为三个部分,分别为 server、web frontend 及数据库。由于 Zabbix 的所有的配置信息都保存在数据库中, server 和 web frontend 可以直接进行操作。
Agent
利用本地系统调用完成统计信息收集。
- 被动(passive)和主动(active)检查
- 被动检查模式中,agent 应答数据请求
- 主动检查模式中,agent 首先进行一次请求 server 或 proxy 索取 item 列表,然后发送对应的值给 server/proxy
Proxy
通常用于替代 server 完成对多个监控设备的监控信息收集工作并将数据发送给 server。所有收集的数据会先存储在 proxy 本地缓存中然后传送给 server。
可以有效的降低在分布式环境中的单一的 server 负载,可以降低 server CPU 和 磁盘I/O 的消耗。能够完成远程区域、分支机构、没有本地管理员的网络的
集中监控。
proxy 使用独立的数据库。 proxy 数据库可以使用 SQLite、MySQL、PostgreSQL。使用 Oracle 或 IBM DB2 在低等级自动发现规则时存在限制和风险,详情 参阅
Java gateway
从 zabbix 2.0 开始,新增 “Zabbix Java gateway”的守护进程提供原生对 JMX 应用的监控。不需要额外安装软件,只需要在启动时指定选项
-Dcom.sun.management.jmxremote 即可
Sender
命令行工具用于发送性能数据给 server
1 | ./zabbix_sender -z zabbix -s 'linux db3' -k db.connections -o 43 |
参数说明:
- z- -指定 server 的 host
- s- -监控 host 名称(在 Zabbix 前段中填写的主机名)
- k- -item 键名
- o- -需要发送的值
Get
用于连接 agent 并从 agent 上检索需要的信息。常用于对 agent 进行 故障检修
Consul
Consul 简介
Consul 可以为基础设施提供 服务发现和配置。核心功能如下:
- 服务发现(Service Discovery)- -客户端提供了能被其他客户端诸如 APi 或 MySQL 等发现的服务。使用 DNS 或 HTTP,应用程序可以很容易的找到 它们所提供的服务
- 健康监测(Health Checking)- -客户端可以提供任何数量的健康监测,可以是给定服务,或是本地节点。此功能可以用来监控集群的通信情况。
- Key/Value 存储- -应用程序可以利用 Key/Value 存储,实现包括动态配置、功能降级、协调、leader election(领导人选举)等。简单的 HTTP API 使得它更易于使用欧冠
- 多数据中心(Multi Datacenter)- -支持开箱即用的多数据中心
Consul 的设计对 DevOps 社区和应用开发者非常友好,使得其非常适合现代的、弹性的基础设施。
具有的优势:
- 使用 Raft 算法来保证一致性,比复杂的 Paoxs 算法更直接。相比较而言,ZooKeeper 采用的是 Paxos,而 etcd 使用的则是 Raft
- 支持多数据中心,内外网的服务采用不同的端口进行监听。多数据中心集群可以避免单点故障,而其部署则需要考虑网络延迟、分片等情况。ZooKeeper 和 etcd 均不提供对多数据中心功能的支持
- 支持健康监测,etcd 不提供此功能
- 支持 HTTP 和 DNS 协议接口。ZooKeeper 的集成较为复杂,etcd 只支持 HTTP 协议
- 官方提供 Web 管理界面,etcd 无此功能。 简单来说,相比 ZooKeeper,Consul 要更轻量,依赖轻(Go 与 Java 的对比),Raft 算法要比 Paxos 算法简单得多,而且效率高。 相比 etcd,Consul 提供了更多的功能,比如 DNS server、多数据中心同步、Web 界面等。
Consul 架构
术语
- Agent
长期运行在每个 Consul 集群成员节点上的守护进程。有 client 和 server 两种模式。所有的 agent 都可以调用 DNS 或 HTTP API,并 负责检查和维护服务同步 - Client
运行 client 模式的 agent,将所有的 RPC 转发到 server。client 是相对无状态的。唯一所做的是在后台参与 LAN gossip pool。 只消耗少量的资源和少量的网络带宽。 - Server
运行 server 模式的 agent,参与 Raft quorum,维护集群的状态,相应 RPC 查询,与其他数据中心交互 WAN gossip,转发查询到 leader 或远程数据中心。 - Datacenter
数据中心,定义数据中心是在同一个网络环境中(私有的、延迟低、高宽带)。 - Consensus
意味着 leader election 机制,以及事务的顺序。由于这些事务基于一个有限状态机,它的定义意味着复制状态机的一致性。 - Gossip
建立在 Serf 之上,提供了完整的 Gossip 的协议,用于成员维护故障检测、事件广播。 - LAN Gossip
指的是 LAN gossip pool,包含位于同一个局域网或者数据中心的节点。 - WAN Gossip
指的是 WAN gossip pool,只包含 server 节点,这些 server 主要分布再把冉的数据中心或者通信是基于互联网或广域网的。 - RPC
远程过程调用。允许 client 请求 server 的请求/响应机制
架构
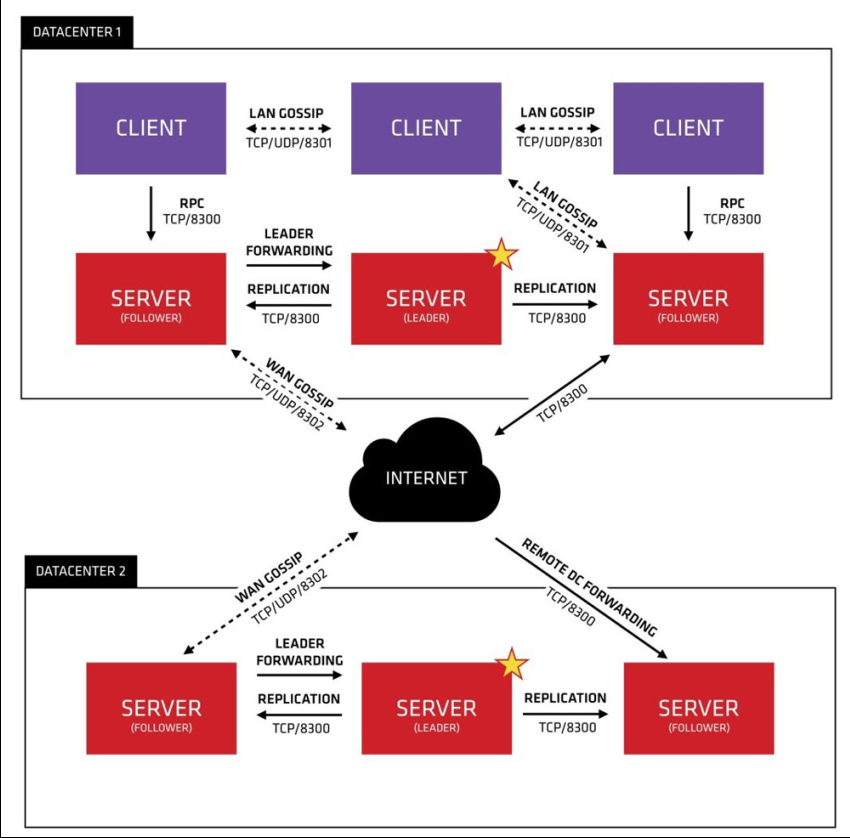 首先,Consul 支持多数据中心(datacenter),从这个架构图可以看到有两个数据中心(datacenter1 和 datacenter2)。
首先,Consul 支持多数据中心(datacenter),从这个架构图可以看到有两个数据中心(datacenter1 和 datacenter2)。
每个数据中心都是由 server 和 client 组成。基于故障处理和性能的平衡的考虑,建议有 3~5 个 server。随着机器的增多,则 consensus 会越来越慢。
对 client 没有限制,可以很容易的扩展。
同一个数据中心的所有节点都要加入 Gossip 协议。这意味着 Gossip pool 包含给定数据中心的所有节点。出于以下目的:
- 没有必要为 client 配置 server、地址参数;发现是自动完成的
- 节点故障检测的工作不是放在 server 上而是分布式的。这使故障检测比心跳机制根据可扩展性
- 当重要的事件发生时,如 leader election(领导人选举),可用来作为消息层的通知
每个数据中心的 server 都属于一个 Raft 对等段。意味着它们一起工作,在他们的中间选出一个 leader,leader 是有额外职责的,需要负责处理所有的 查询和事务。事务也必须通过 consensus 协议复制到所有的伙伴中。由于这要求,当非 leader server 接收到一个 RPC 请求时,会转发到集群的 leader 中。
server 节点也作为 WAN gossip pool 的一部分。这个 pool 与 LAN pool 不同,它为具有更高延迟的网络响应做了优化,并且可能包含其他 Consul 集 群的 server 节点。设计 WAN gossip pool 的目的是让数据中心能够 low-touch(低接触)的方式发现彼此。将一个新的数据中心加入到现有的 WAN Gossip 中很容易。因为 pool 中所有 server 是可控制的,因此能够满足跨数据中心的要求。当一个 server 接收到不同的数据中心的要求时,把这个请求 发送给相应数据中心的任一 server。然后,接收到请求的 server 可能会转发给本地 leader。
多个数据中心之间是低耦合的,由于需要满足故障检测、连接缓存和多路复用等需求,跨数据中心被设计为能够快速和可靠的响应请求。
Consul 的安装和使用
从官网下载 Consul 安装包,根据系统选择下载。(备用下载地址)
下载完成后,解压安装包到指定路径,并配置 PATH
相关推荐:
Consul agent
Consul agent 是 Consul 的核心进程。其作用包括维护成员信息、注册服务、运行检查、响应查询等。必须在 Consul 集群的每个节点上运行。
agent 可以以 client 或者 server 模式运行。server 模式运行的节点用于维护 Consul 集群的状态,提供故障情况下的 强一致性和可用性。 client 模式则相对轻量很多,只需维护自身的状态。
ZooKeeper
ZooKeeper 分布式服务框架是 Apache Hadoop 的一个子项目,主要用来解决分布式应用中经常遇到的一些 数据管理 问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。ZooKeeper 的目标是封装好复杂易出错的关键服务, 将简单易用的接口和性能高效、功能稳定的系统提供给用户
ZooKeeper 简介
ZooKeeper 是分布式应用的高性能 协调服务(coordination services)。
- 设计目标
- 操作简单
主要用来协调分布式任务(通过一个叫做多层次的命名空间,类似文件系统)。一个命名空间就是一个数据存储器,称为 znode。多层次的命名空间就是 文件与目录的关系。由于数据保存在内存中,可以实现高吞吐量和低延迟。 - 自我复制
各个 server 间复制数据 - 有序
通过更新一个计算器来反应 ZooKeeper 的事务顺序,子操作可以通过这个计数器来实现更高层次的抽象 - 快速
- 操作简单
- 数据模型和多层次命名空间
- ZooKeeper 节点和临时节点
ZooKeeper 的节点是通过像树一样的结构来进行维护的,并且每一个节点通过路径来标识和访问。一般使用 znode 来表示 ZooKeeper 节点。
znode 通过管理包含数据、ACL(access control list,访问控制列表)、时间戳的版本号数据结构,来实现缓存生效以及协调更新。
同时 znode 具有原子性操作的特定: 命名空间 中,每一个 znode 的数据将被原子的读写。
临时节点与 session 同时存在,当 session 生命周期结束,这些临时节点也将被删除。 - 有条件的 update 和 watch
client 可以在 znode 上设置 watch。当 znode 变更时,watch 将被触发并移除。 - 保证
ZooKeeper 的速度非常快,非常简单。为了支持复杂的服务,提供了以下保证:- Sequential Consistency(顺序一致性)–client 的更新将在它们应用时按照顺序进行发送
- Atomicity(原子性)–更新非成功即失败
- Single System Image(单一系统映像)–client 看到的服务视图相同
- Reliability(可靠性)–当更新开始,会从哪个时候起一直持续,直到 client 再次更新为止
- Timeliness(时效性)–client 视图保证在一定时间内是最新的
- API 简单
支持以下操作:- create–在树中的位置创建一个节点
- delete–删除一个节点
- exists–测试一个节点是否出现在某个位置
- get data–从一个节点上读取数据
- set data–写入数据到节点
- get children–检索节点的子节点的列表
- sync–等待数据被传播
- 实现
ZooKeeper 组件
除了请求处理器(request processor),构成 ZooKeeper 服务的每个服务器都有一个备份。
复制的数据库(replicated database)是一个内存数据库,包含整个数据树。为了可恢复,更新会被记录日志到磁盘,并且在更新这个内存数据库之前,先 序列化到磁盘。
client 的读请求直接由本地的复制数据库提供数据。对服务状态进行修改的请求、写请求通过一个约定的协议进行通信。
作为这个协议的一部分,所有的写请求都被传送到一个叫“leader”的 server,而其他的 server 叫作“follower”。follower 从 leader 接收信息修改 的提议,并决定是否同意进行修改。当 leader 发生故障时,协议的信息层(messaging layer)关注 leader 的替换,并同步到所有的 follower。
ZooKeeper 采用自定义的信息原子操作协议,这能保证本地的复制数据库不会产生不一致。当 leader 接收到一个写请求时,计算出写之后系统的状态,将其变 成一个事务。
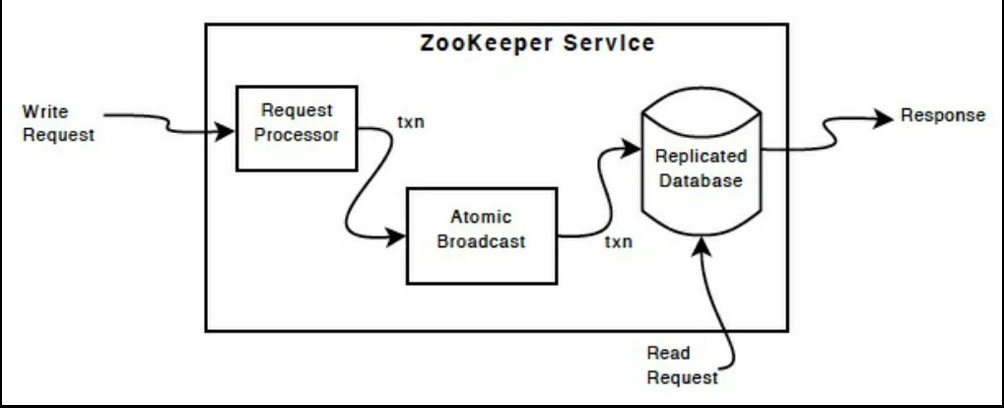
ZooKeeper 的安装和使用
ZooKeeper 的内部工作原理
-
原子广播
ZooKeeper 的核心就是消息处理的原子性,能够保持所有的 server 同步 -
保证、属性和一些定义
能够保证消息处理原子性的特性包括:- 可靠的消息传递
- 顺序接收
- 因果关系
使用 timeout 机制,既保证了一致性,也证明了 server 的存活,当 timeout 机制停止工作(计时发生故障)时,消息系统会挂起,但依然能够保证一致性 正常工作。
描述 ZooKeeper 消息协议时,使用到以下的概念:
- 数据包
通过FIFO(先进先出)通道发送的一系列字节流 - 提议(Proposal) 一个协议单元,提议通过 ZooKeeper server 的 quorum 交换数据包来表决。大多数提议包含消息。个别的就是 NEW_LEADER 协议不带消息,ZooKeeper 使用事务 id(zxid 用一个 64bit的数字实现–epoch(高32位)和计数器(低32位)) 来保证提议的顺序
- 消息 字节流会自动广播到其他 ZooKeeper server。提议和同意提议在传递的时候都会附带消息
确认了 ZooKeeper 的协议就意味着 server 持久化存储提议。quorum 要求任何一个 quorum 至少有一个 server。至少一半以上的 server 同意该提议, 提议才有效。
ZooKeeper 消息系统由两部分组成:
- leader 激活–需要选举一个 leader,然后建立正确的系统状态,准备好接受提议
- 消息传递–leader 接受提议,同时协调提议的正确传递
- leader 激活
leader 激活包括 leader election。leader election 算法包括:LeaderElection 和 FirstLeaderElection(AuthFastLeaderElection 通过 UDP 通信,允许各个 server 使用一组简单的认证方式来避免 IP 欺骗)。
leader 选举需要满足以下要求:- leader 的 zxid 必须是 follower 中最高的
- 将法定数量的 server 提交给 leader
leader 激活过程的操作步骤: - follower 在和 leader 同步后,会确认收到一个 NEW_LEADER 提议
- follower 在收到一个单独 server 的特定的 zxid 的 NEW_LEADER 提议时才会确认
- 当法定数量的 follower 都确认后,新的 leader 将提交 NEW_LEADER 提议
- 当 NEW_LEADER 提议提交后,follower 就会提交接收自 leader 的状态
- leader 在 NEW_LEADER 提议被提交通过后,才接收其他新的提议
- 激活消息
激活是最繁琐的。 - quorum(投票)机制
quorum 保证了自动广播和 leader election 的系统一致性。默认的,ZooKeeper 采用 majority quorum(多数派投票机制),这以为着每次提议的 投票必须有多个 server 通过。 分层系统中,使用 权重加权 构造系统的构造被广泛使用。 - 日志
使用 slf4j 作为日志的抽象层,默认使用 log4j 1.2 来做实际的日志工作。
slf4j 主要有以下几个日志级别:- ERROR
- WARN
- INFO
- DEBUG
- TRACE
分布式版本控制系统
- 版本控制系统简史
版本控制工具发展已经有几十年了,简单的可以分为四代:- 文件式版本控制系统–如:SCSS、RCS
- 树状版本控制系统–服务器模式,如:CVS
- 树状版本控制系统–双服务器模式,如:Subversion
- 树状版本控制系统–分布式模式,如:Bazaar、Mercurial、Git
- 集中式 VS. 分布式
传统的版本控制工具都需要一个 中心服务器 来存放一系列文件及其更新日志。为了能够记录或提交工作,用户必须连接到中心服务器并且能确保提交的能够与 试图提交前的最新版本兼容,这就是所谓的集中式。集中式的 VCS 必须确保当用户想要对版本进行修改时可以 连接 到服务器。其次,集中式必须紧紧的依赖 修改和发布的行为,这在某些情况是好的,但也可能影响其他使用者的工作质量。
分布式 VCS 允许用户和团队拥有多个目录而不是只有一个中心目录。用户可以在代码有效的情况下随时提交代码,即使是离线模式。
分布式 VCS 的优势包括:- 更容易的创建分支
- 极其容易的与他人合作
- 节约机械式任务的时间
- 通过使用“广泛特性”协议来不断提高发布管理的灵活性
- 主版本的质量和稳定性会更好,减小了所有人的压力
- 在开放的社区中
- 方便没有非核心开发者创建和维护更新
- 方便核心开发者与非核心开发者合作
- 分散的和外包的队伍的工作将会更方便
Bazaar
Bazaar 简介
Bazaar 是协调工作的工具,能够检测同一组文件。这样的工具也被称为 版本控制系统(Version Control System,VCS)。
Bazaar 的特点:
- 易于使用
- 支持离线工作
- 支持任意工作流
- 跨平台
- 支持重命名跟踪和只能合并
- 高存储效率、高速度
- 支持任意工作区间
- 客户端和命令可以支持 Subversion、Git 和 Mercurial 仓库的外部分支
- 支持 Launchpad
- 支持插件和 bzrlib
Bazaar 的核心概念
主要包含四个核心概念:
- Revision(修订版)–被修改文件的快照(snapshot)
- Working tree(工作树)–存储需要做版本控制的文件(目录和子目录)
- Branch(分支)–按顺序存放的修订版来记录一系列文件的修改历史
- Repository(版本库)–存放修订版的存储库
- Revision
一个修订版就是一系列文件和目录的独立的镜像,包括他们的内容和大小。一个修订版还有一些与之相关的属性,包括:- 提交者
- 提交时间
- 提交的信息
- 来源于哪个修订版 修订版是不可变的,在全局唯一的修订 id 号。修订 id 号是在提交或者在其他系统中转移来时生成的。
- Working Tree
存放了用户能够编辑的文件的版本收集目录,并且会与特定的一个分支结合在一起。 - Branch
一个分支就是一系列有序的修订版。最新的修订版被称为顶端(tip)。
多个分支既可以被分割开,也可以重新合并(merged)共同组成一个修订版的图(graph)。专业说法: 这个图应当是有向的(用以展示双亲版本和儿子修订版 的关系)并且是无环的, 也就是常说的有向无环图(directed acyclic graph,简称 DAG) - Repository
仓库就是存储修订版文件的地方。
Bazaar 的安装
Bazaar 的使用
Mercurial
Mercurial 简介
Mercurial 是一个免费的轻量级分布式版本控制系统,采用 Python 语言实现,易于学习和使用,扩展性强。
相较于传统的版本控制,具有以下优点:
- 更轻松的管理–每个用户管理自己的仓库,管理员只需要协调同步仓库
- 更健壮的系统
- 对网络依赖性更低
Mercurial 的核心概念
- Repository
包含一个工作目录和一个存储。存储包含项目的完整历史记录。 - 提交更改
当提交时,工作目录相对于其父节点的状态被记录为新的变更集(changeset),也称为新的“修订版(revision)” - revision、changeset、head 和 tip 将多个文件的更改归类为单个原子变更集(changeset),
- clone、标记更改、merge、pull 和 update
- 一个分散的系统
Mercurial 的安装
Mercurial 的使用
相关推荐:
Git
Git 简介
Git 是 Linus Torvalds 帮助管理 Linux 内核开发而开发的一个开放源码的版本控制软件。
Git 的安装
Git 易于安装,可以从Git 官网下载。同时有相关安装教程。
Git 的基础概念
- 直接记录快照,而非差异比较
Git 和其他版本控制系统的主要差别在于 Git 对待数据的方法。
大部分系统以文件变更列表的方式存储信息,这类系统(CVS、Subversion、Perforce、Bazaar 等)将保存的信息看做一组基本文件和每个文件随时间逐步 累积的差异。
Git 对当时的全部文件制作一个快照并保存这个快照的索引。因此对待数据更像是一个快照流(a stream of snapshots) - 几乎所有操作都是本地执行的
- Git 能保证完整性
所有的数据在存储前都计算校验和,然后以校验和来引用。这种计算机制叫作SHA-1 散列(hash,哈希)。这是一个由 40 个十六进制字符(0-9和 a-f) 组成的字符串,基于 Git 文件的内容或目录结构计算出来。 - Git 一般只添加数据
执行的 Git 操作几乎只往 Git 数据库中增加数据。 - 三种状态
Git 有三种状态: 已提交(committed)、已修改(modified)、已暂存(staged)。- 已提交–数据已经安全的保存在本地数据库中
- 已修改–修改了文件,但还没保存到数据库中
- 已暂存–已修改文件的当前版本做了标记,使之包含在下次提交的快照中 Git 项目的三个工作区域的概念: Git 仓库(directory 或 repository)、工作目录(working directory)以及暂存区域(staging area)。
- 仓库目录–用来保存项目的元数据和对象数据库。克隆仓库,复制的就是这里的数据
- 工作目录–是对项目的某个版本独立提前出来的内容
- 暂存区域–是一个文件,保存了下次将提交的文件列表信息,一般在 Git 仓库目录中。有时也被称作“索引”。 基本的 Git 工作流程:
- 在工作目录中修改文件
- 暂存文件,将文件的快照放入暂存区域
- 提交更新,找到暂存区域的文件,将快照永久性存储到 Git 仓库目录
Git 的使用
RESTful API、微服务及容器技术
Spring Boot
Spring Boot 旨在简化创建产品级的 Spring 应用和服务。Spring Boot 为 Spring 平台及第三方库提供开箱即用的设置。
Spring Boot 也是构建微服务的框架,在 Spring Boot 中实现一个基于 HTTP 的 RESTful 微服务,只需要简单的加入 actuator 与 Web 启动 模块即可。
Spring Boot 简介
Spring Boot 所提供的众多便捷功能,都是借助于 Groovy 强大的 MetaObject 协议、可插拔的 AST 转换过程及内置了解决方案引擎所实现的依赖。
Spring Boot 项目主要的目的:
- 为 Spring 的开发提供了更快、更广泛的快速上手
- 使用默认方式实现快速开发
- 提供大多数项目所需的非功能特性,诸如嵌入式服务器、安全、心跳检查、外部配置等
- 绝对没有代码生成(code generation),也不需要 XML 配置
Spring Boot 的安装
Spring Boot 的使用
Docker
Docker 是 Go 语言编写的。采用 Apache Licence V2 开源协议。
Docker 简介
Docker 提供了一种方法来运行在容器中安全隔离的应用程序。应用程序与其所有的以来和库将被一起打包,因此整个构建过程是完全移植的。
典型的 Docker 平台工作流程:
- 将代码及其依赖项添加到 Docker 容器中
- 编写指定执行环境并 pull 代码的 Dockerfile
- 应用程序有依赖于外部应用程序(如 Redis 或 MySQL),只需在 registry(例如 Docker Hub)中找到它们,在 Docker Compose 文件中引用它们
并引用应用程序,以便同时运行
- 软件提供商还可以通过 Docker Store 分发付费软件
- 构建项目,然后在开发时通过 Docker Machine 在虚拟主机上运行容器
- 如果需要,可以为解决方案配置网络和存储
- 将构建版本上传到 registry(用户自己或者其他云提供商),以与团队协作
- 如果需要在多个主机(VM 或物理机)上扩展解决方案,应计划如何设置 Swarm 集群并扩展以满足需求 使用 Universal Control Plane,可以使用友好的界面来管理 Swarm 集群
- 最后,使用 Docker Cloud 部署到首选的云提供商(为了冗余 ,可以部署到多个云提供商),或者使用 Docker Datacenter 部署到用户的内部部署硬件。
Docker 的特性
Docker 是开发人员和系统管理员用于开发、送输和运行应用程序的平台。允许用户快速组装组件中的应用程序,并消除运输代码过程中可能出现的不一致问 题。可以让代码尽可能从测试和部署环境转移到生产环境。
Docker 由以下几部分组成:
- Docker Engine–轻量级和强大的开源容器化技术,结合了构建和容器化应用程序的工作流程
- Docker Hub–提供的 SaaS 服务,用于共享和管理应用程序堆栈
Docker 包含如下特性:
- 更快的交付应用程序 * Docker 容器机器附带的工作流程可帮助开发人员、系统管理员、QA 人员和发布工程师协同工作,将代码尽快投入生产。Docker 提供了一个标准容器格式, 让开发人员可以仅关注在容器中的应用程序,而系统管理员和操作员可以在部署中运行容器。这种指责分离简化了代码的管理和部署 * 用户可以轻松构建新容器,实现应用程序的快速迭代,并提高了变更的可见性。有助于组织中的每个人了解应用程序的工作原理及构建方式
- 更容易部署和扩展 * Docker 容器几乎可以运行在任何环境 * 容易移植应用程序 * 可以快速、轻松的缩放规模
- 获得更高的密度和运行更多的工作负载 * Docker 容器不需要管理程序,因此可以将更多的容器打包到主机上
- 更快的部署使得管理更容易 * 加速了用户的工作流程,变得更容易做许多小的更改,避免了巨大的、爆发式更新。这也降低了升级风险
Docker 的概念和原理
Docker Engine
是客户端-服务器模式的应用程序,具有以下主要组件:
- 一个服务器,是长时间运行的程序,称位守护进程
- 一个 REST API,指定了程序可以用来与守护程序通信的接口,并可以指示执行的操作
- 命令行界面(CLI)客户端
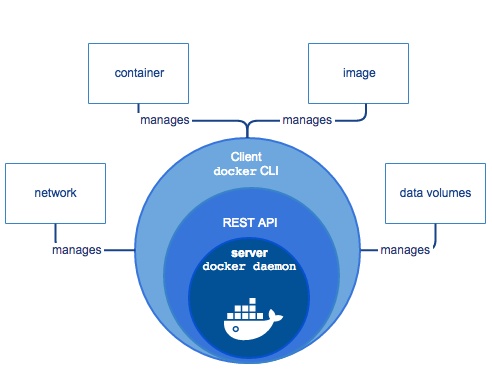
Docker 组件
CLI 使用 Docker REST API 通过脚本或 CLI 命令来控制或与 Docker 守护进程交互。 守护进程创建和管理 Docker 对象,如镜像(image)、容器、网络和数据卷Docker 的架构
Docker 使用客户端-服务器(C/S)模式的架构。Docker 客户端和守护程序可以在同一系统上运行,也可以将 Docker 客户端连接到远程 Docker 守护程序。 通过 socket 或 通过 REST API 进行通信。
Docker 架构图
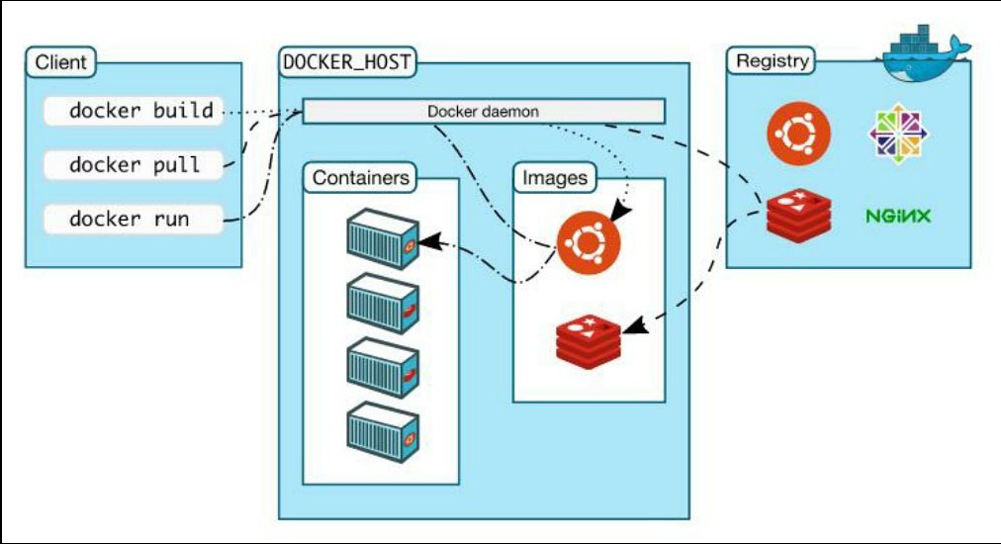
- Docker 守护进程–Docker daemon
- Docker 客户端–Docker client,获取用户的命令和配置标识,并与服务器进行通信。可以与多个不相关的服务器进行通信。
- Docker 镜像–Docker image 是一个只读模板,包含了用于创建 Docker 容器的说明。用户可以自定义构建或更新 image,也可以下载并使用他人
创建的 image。image 可以基于或扩展一个或多个其他的 image。Docker image 在文本文件中被称为 Dockerfile。
Docker image 是 Docker 的 构建 组件。 - Docker 容器–Docker container 是 Docker image 的可运行实例。用户可以使用 Docker API 或 CLI 命令运行、启动、停止、移动或删除容器。
运行容器时,可以提供配置元数据。每个容器是一个隔离、安全的应用程序平台,但可以访问在不同主机或容器中运行的资源,以及持久存储或数据库。
Docker container 是 Docker 的 运行 组件 - Docker 注册中心–Docker registry 是一个 image 库。可以是私有的或公共的,并可以与 Docker 守护程序或 Docker 客户端在相同的服务器上,
也可以在完全独立的服务器上运行。
Docker registry 是 Docker 的 分发 组件
Docker image 的工作原理
每个 image 由一系列层组成。Docker 使用 union file system(联合文件系统)将这些图层组合成单个 image。union file system 允许单个文件 系统的文件和目录(成为分支)被透明的覆盖,形成单个一致的文件系统。
要分发更新,只需传输要更新的层。分层加速了 Docker 镜像的分支。Docker 会确定哪些层需要在运行时更新。
基本 image 是使用 dockerfile 中的 FROM 关键字来定义的。
Docker Hub 是一个公共的 registry,用于存储 image。
image 是使用 instruction(指令)的简单的描述性步骤从基本 image 来构建的,这些步骤存储在 Dockerfile 中。每个 instruction 在 image 中 创建一个新层。当请求构建影响,执行 instruction 并返回 image 时,Docker 会读取此 Dockerfile。
Docker registry 的工作原理
用于存储 Docker image。
容器工作原理
使用主机的 Linux 内核,包含了在创建 image 时添加的所有额外文件,以及创建或启动容器时与容器关联的元数据。每个容器由 image 构建。当 Docker 从 image 运行容器时,会在应用程序运行的 image 顶部(使用 union file system)添加一个读写层。
Docker 的底层技术
- 命名空间
使用命名空间(namespace)技术来提供容器的隔离工作空间。当运行一个容器时,Docker 为该容器创建一组命名空间。
容器的每个方面都运行在单独的命名空间中,并且其访问仅限于该命名空间。 - 控制组
Linux 上的 Docker Engine 依赖于控制组(control groups,简称cgroups)的技术。控制组将应用程序限制为一组特定的一组资源。控制组允许 Docker Engine 将可用的硬件资源共享到容器,并且可选的实时限制和约束。 - 联合文件系统
联合文件系统(Union file system,简称UnionFS)是通过创建层来操作的文件系统。Docker Engine 使用 UnionFS 提供容器的构建快。Docker Engine 可以使用多个 UnionFS 变体,包括 AUFS、btrfs、vfs 和 DeviceMapper。 - 容器格式
Docker Engine 将命名空间、控制组和 UnionFS 组合成一个称为容器格式的包装器。默认格式为 libcontainer。
Docker Engine 的安装
Docker 的使用
-
2021-03-01
Docker 部署安装
-
2023-07-14
如何使用 AWS 的 kafka 服务?
-
2021-02-26
docker 容器学习
-
2023-07-14
如何在 AWS 上通过 Peering Connections(对等连接) 使用 Atlas Mongodb 服务?
-
2022-11-10