
TDD 学习-知识汇总
TDD 是测试驱动开发的英文简称,是敏捷开发中的一项核心实践和技术,也是一种设计方法论。
TDD 理论知识
基础知识
TDD 是一种设计和开发方法,帮助我们从项目开始就构建出可运行的软件,并且以增量的方式添加新功能。
TDD 原则:编写代码只是为了修复失败的测试
Write new code only if an automated test has failed
TDD 周期: 测试 -> 编码 -> 重构 (测试先行),主要概念:
- 单元测试(Given-When-Then)
- “单元测试/编写代码”循环
- 重构
TDD 特点:
- 增量式开发
以增量方式构建整个系统,距离已集成的、可工作的状态不会太远,也可降低风险。 - 增量式演化设计
在系统不断添加更多的功能和行为的过程中,不断地微调代码结构。在代码生命周期的任何时刻,代码所展现的都是为完成现有功能所做的最好的设计。 用这种方法,可以演化出能经受实践检验的架构。 - 演进式设计
通过小步的前进,在开发过程中逐渐地演化出最适合当前需求的架构。同时可以提高设计质量,从而提高整个系统的质量。
TDD 优点:
- 永远不会忘记接下来做什么–重新运行测试就知道要做的事情了
TDD 难点:
- 分解问题
- 找到子问题之间的关联(通过输入、输出关联起来)
- 找到问题的边界,明确假设与结果
TDD 流程:
- 创建一个清单,列出所知道的需要让其运行通过的测试
- 设计对象关系图
- 通过一小段代码说明我们希望看到怎样的一种操作
- 暂时忽略单元测试的一些细节问题
- 通过建立存根(stub)来让测试程序通过编译
- 通过一些另类的做法来让测试运行通过
- 将新工作逐步加入计划清单,而不是一次全部提出
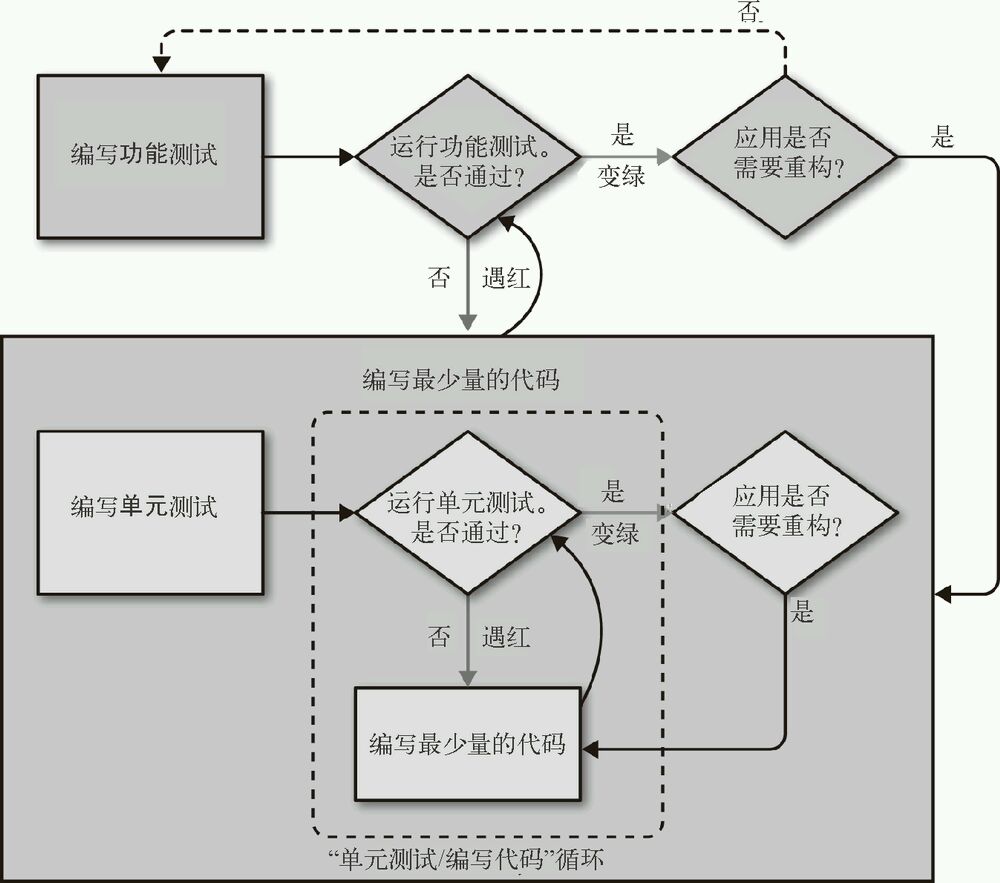
描述 TDD 流程的另一种方式:- 遇红/变绿/重构
先编写一个测试让它失败(遇红),然后编写代码让测试通过(变绿),最后重构(改进实现方式)。
- 遇红/变绿/重构
回归
返回到更初级的状态。在软件开发领域,回归表明已有的、曾经可用的功能不再能正常运转,即从正常工作状态退化到不能工作的状态。 回归不会平白无故的发生,都是代码修改后引入了缺陷才会出现回归。因此必须依靠测试套件。
- 测试套件
- 在代码周围形成了一个模子。如果代码的改动破坏了功能,模子就不再符合了。若出现破损,也可以通过测试知道问题出现在何处。
- 特点:
- 容易运行
- 能快速执行(快速获得反馈)
测试
- 把测试作为沟通的共同语言
- 用自动化测试做保护
- 回归测试(Regression Test)
在代码的修改后,随时可以执行所有测试(测试套件),测试失败了则可快速定位问题。 - 好的测试是独立的
- 好的测试时原子化的
- 单元测试由功能测试驱动,而且更接近真正的代码
- 以测试用例为规约
测试的最佳实践
- 确保测试隔离,管理全局状态
- 避免使用“含糊的”休眠
有时没法快速的完成所有测试。在这种情况下,可以选择运行一部分测试(通常是最可能发现当前改动所引发缺陷的那部分测试); 让构建服务器(build server,也称 continuous integration 持续集成服务器)在后台运行所有测试(单元测试、集成测试、功能测试)。 拥有持续集成服务器并不代表拥持续集成。持续集成服务器可以是构建过程自动化,还能产生精美的报表。
-
持续集成服务: Jenkins
-
持续集成:是指开发人员频繁的继承修改过的代码,使得集成几乎是持续的。
-
代码覆盖率
通过工具来检测源代码中的问题或者分析源代码的复杂性
需要合理的代码覆盖率
相关推荐:
在编写测试前,需要先弄清楚测试的目标,即实现的功能。然后将功能分解为需求
- 传统的需求分解成任务;TDD 模式将需求分解为测试,创建测试列表
| 把模板子系统分解成任务(传统模式) | 把模板子系统分解成测试(TDD模式) |
|---|---|
| 写一个正则表达式以确定模板中的变量 | 没有任何变量的模板,渲染前后内容不变 |
| 实现一个使用正则表达式的模板解析器 | 实现一个模板引擎,引擎对外暴露一组API,内部实现使用模板解析器 |
| 含有一个变量的模板渲染后,变量应当替换为相应的值 | 含有多个变量的模板渲染后,变量应当替换成相应值 |
| ... | ... |
当在编写一个测试时,发现功能实现的不正确,或者整块缺失等问题,可以先把问题记录下来,继续手中的工作。这样可以集中注意力完成一项任务,而不是在几项任 务间来回切换。
功能测试
功能测试(functional test) = 验收测试(acceptance test) = 端到端测试(endto-end test)
ATDD(Acceptance Test Driven Development) 的总体流程:
- 编写一个测试程序。编写一个故事,包含任何所有能想象到的、计算出正确结果所必需的的元素。
- 让测试程序运行,并快速实测实通过。
- 伪实现(bogus implementation) – 返回一个常量并逐渐用变量代替常量,至值伪实现代码称为真实实现的代码
- 显明实现(obvious implementation) – 将真实的实现代码键入
- 三角法(triangulation) – 根据两个例子(暂时不清楚实际语义,待查阅英文版本)
- 适用于完全不知道该如何重构
- 变现合格的代码(消除重复设计,优化设计结构)
编码
完成系统的途径: 深度优先 和 广度优先
算法遍历树: 广度优先遍历,深度优先遍历
- 广度优先:集中实现高层的功能,实现过程中会暂时使用底层功能的伪实现。
- 先针对 Template 类的公共接口写测试,然后使用内部和底层功能的伪实现让测试通过,接着再去给下一层的功能写测试。
- 深度优先:集中实现底层的功能,在所有底层功能都实现完成后才会组合起来实现出高层功能。纵向的实现功能的所有细节,一步步向前推进。
- 先针对模板解析逻辑写测试。模板解析功能完成后再开始其他测试。
意图编程: 将注意力集中在能有的,而不是已经有的东西上。
重构
定义:
- 名词形式: 对软件内部结构的一种调整,目的是在不改变软件可观察行为的前提下,提高其可理解性,降低其修改成本。
- 动词形式: 使用一系列重构手法,再不改变软件可观察行为的前提下,调整其结构。
- 主要目的:消除重复
- 方法:
-
消除重复法
-
三角法: 从多个角度同时入手,共同确定出恰当的实现方法。可以防止过早优化、功能蔓延(软件过分强调新的功能,以至于损害了其他的设计目标, 例如简洁性、轻巧性、稳定性及错误出现率等)以及总体上的过度设计。
-
重命名法
Refactoring is making changes to a body of code in order to improve internal structure, without changing its external behavior.
-
TDD with Django
- 用户故事
从用户的角度描述应用应该如何运行。用来组织功能测试 - 预期失败
意料之中的失败 - 意外失败
意料之外的失败。意味着测试中有错误,或者测试帮我们发现了一个回归,因此要在代码中修正 - 测试代码尽量简单
- 功能测试
作用是帮助开发具有所需功能的应用,还能保证不会无意破坏这些功能。单元测试的作用是帮助编写简洁无错的代码。 - 功能测试的调试技术
- 改进错误消息
- 手动访问网站
- 等待时间(time.sleep)
- 把工作分解成易于实现的小任务
- 必要时做少量的设计
- 不要预先做大量设计
- 'YANGI’-(读作yag-knee) You ain’t gonna need id <你不需要这个>,不要编写当时看起来可能有用的代码
- REST(式)-representational state transfer
- 事不过三,三则重构
- 判断何时删除重复代码时使用的经验法则。如果两个段代码很相似,往往还要等到第三段相似代码出现,才能确定重构时哪一部分是真正共同、可重用的。
- 记在便签上的待办事项清单
- 在便签上记录编写代码过程中遇到的问题,等手头的工作完成后再回过头来解决。
- 更好的单元测试实践方法: 一个测试只测试一件事,但有时断言之间联系紧密,可以放在一起。
- 确保测试隔离,管理全局状态
- 不同的测试之间不能彼此影响,也就是说每次测试结束后都要还原永久状态。
- 避免使用“含糊的”休眠
- 一旦需要等待什么加载,第一反应是使用 time.sleep。但是这样做带来的问题是,时间的长度无法确定:要么太短,容易导致假失败;要么太长,会拖慢测试。 推荐使用重试循环,可以轮询应用,尽早向前行进。
功能测试新工具:通用显式等待辅助方法
- 将测试放在单独的文件夹中
- 对功能测试来说,按照特定功能或用户故事的方式组织
- 对单元测试来说,使用一个名为 ‘tests’的文件夹,并创建
__init__.py文件使其成为 python 包 - 针对一个源码文件的测试放在一个单独的文件中。在Django中往往有test_models.py、test_views.py、test_forms.py
- 每个函数和类都至少有一个占位测试
- 编写测试的主要目的是重构代码。尽量让代码(包括测试)变得简洁。
- 单元测试失败时不能重构
一般情況下:
* 如果测试的对象还没实现,可以先为测试方法加上 @skip 装饰器
* 更常见的做法是:记下想重构的地方,完成已有的,等应用处于正常状态时重构
* 提交代码之前需要删除所有@skip装饰器
- 尝试通用的 wait_for 辅助方法
- 使用专门的辅助方法实现显式等待。能让测试更易于阅读,但有时单行断言或Selenium交互也需要等待一段时间。
- 将辅助函数放在使用的功能测试类中,仅当辅助函数需要在别处使用时,才放在基类中,以防止基类太臃肿。 (这就是YANGI原则)
单元测试要测试的是:逻辑、流程控制和配置。不要测试常量,应该测试实现方式 编写断言检测 HTML 字符串是否有指定的字符,不是单元测试应该做的。
Django相关
-
MVC
Django 遵循了经典的 模型-视图-控制器(Model-View-Controller)模式,但并没严格遵守。 -
工作流程
- 针对某个URL的HTTP请求进入
- Django使用一些规则决定由哪个视图函数处理这个请求(这一步叫作解析URL)
- 选中的视图函数处理请求,然后返回HTTP响应
因此要测试两件事: 能否解析网站路径的URL,将其对应到编写的视图函数
能否让视图函数返回一些HTML -
安全
- 跨站请求伪造(Cross-Site Request Forgery, CSRF)漏洞
-
Django ORM
- 对象关系映射器(Object-Relational Mapper)
- ORM 的任务是模型化数据库 创建数据库其实是由另一个系统负责的,叫作迁移(migration),makemigraitons 创建迁移
-
测试
- factory_boy 自动创建模拟数据
待学习知识
部署 (deploy)
- Solid Python Deployments for Everybody “Hynek Schalawack”
- Git-based fabric deploys are awesome “Dan Bravender”
- Two Scoops of Django # deploy content
- The 12-facotr App
自动部署
- fabric3
允许在 Python 脚本中编写可在服务器中执行的名。这个工具很适合自动执行服务器管理任务 - 把配置文件纳入版本控制
- 自动配置
- 配置管理工具
- Salt
- Puppet
前端
-
Bootstrap
- LESS or Sass to customize bootstrap
-
客户端打包工具
- npm and bower
安全
- fail2ban(服务器安全工具)
生产环境和开发环境中使用不同的密钥是个好习惯
生产服务器环境
- 不要在生产环境中使用 Django 开发服务器,使用 Gunicorn 或者 uWSGI
- 使用 Ningx 处理静态文件
- 检查 settings.py 中只针对开发环境的设置
- 安全性
使用Git标签标注发布状态 为了保留历史标记,使用Git标签(tag)标注代码库的状态,指明服务器中当前使用的是哪个版本
1 | git tag LIVE |
Web 应用的验证可以放在两个地方:
- 客户端(JavaScript或HTML5属性)
- 服务器端
在服务器端,对Django而言,也有两个地方可以执行验证:一个是模型层,一个是表单层,位置较高
如果想检查某件事是否会抛出异常,可以使用self.asserRasies上下文管理器
在渲染表单的视图中处理改视图接收到的Post请求
with 上下文管理器如何使用
-
上下文管理协议(Context Manager Protocol)
包含方法__enter__()和__exits__(),支持该协议的对象要实现这两个方法 -
上下文管理器(Context Manager)
支持上下文管理协议的对象,这种对象实现了上述两种方法。上下文管理器定义执行with语句时要建立的运行时上下文,负责执行with语句块上下文中的进入与退出操作。1
2with EXPR as VAR:
BLOCK
Django URL 反向解析
- 每个模型对象都对应一个特定的 URL,因此可以定义一个特殊的函数,命名为 get_absolute_url,其作用是获取显示单个模型对象的页面 URL
关于数据层验证
- 数据库层验证是数据完整性的最终保障
- 但是数据库层验证有失灵活性
- 对用户不太友好(表单验证考虑到了用户,不会直接报错,而是显示友好的错误消息)
表单验证
-
可以处理用户输入,并验证输入值是否有错误
-
可以在模板中使用,用来渲染HTML input元素和错误消息
-
表单甚至可以把数据存入数据库
表单是放置验证逻辑的绝佳位置。 -
前端开发 angular.js 和 React(MVC) 框架
这些框架的教程大都使用一个 RSpec 式断言库,名为 Jasmine。MVC 框架,使用 Jasmine 比 QUnit 更方便
JavaScript测试
- Selenium 最大的优势之一是可以测试 JavaScript 是否真的能使用,就像测试 Python 代码一样。
- JavaScript 测试运行库有很多,QUnit 和 jQuery 联系紧密
主要的挑战
- 管理全局状态。这包括:
- DOM/HTML固件
- 命名空间
- 理解并控制执行顺序
无密码验证系统的原理是,只使用电子邮件地址确认身份
TDD: 模拟技术和测试隔离
创建 spike '探索' 分支,使用 django的mvc模式尽快测试功能是否可行,并创建相应的 版本分支, 测试可行后,回归到正式分支中,
开始TDD流程:创建功能测试->单元测试(Js测试)->编写代码
模拟技术: 测试外部依赖(例如邮件)的关键技术
-
探究
为了学习新API或调查新方案的可行性而做的探索性编程。没有测试也能探究。最好在一个新分支中去探究,去掉探究代码时再回到主分支。 -
去掉探究代码
把探究所得应用到实际代码中
要完全摒弃探究代码,然后从头开始,用 TDD 流程再实现一次。去掉探究代码后实际编写的代码往往与最初有很大不同,通常会更好。 -
针对探究代码编写功能测试
该不该这么做要视情况而定。支持这么做的人人为,这样有助于正确编写功能测试–找出测试探究的方法与探究本身一样具有挑战性;不支持这么做的人觉得这样 会阻碍思路,写出的代码往往与探究时很像 – 我们要力求避免这种情况。使用测试数据预先填充数据库的过程,例如存储 User 对象及其相关的Session对象,叫做设置“测试固件”(test fixture)
显式等待辅助方法最终版:wait装饰器
不同测试类型以及解耦 ORM 代码的利弊
集成测试(integration test)和整合测试(integrated test)的区别:
-
功能测试(验收测试、端到端测试)
- 从用户的角度出发,最大程度上保证应用可以正常运行
- 但是反馈时间用时长
- 无法帮助我们写出简介的代码
-
整合测试(依赖于ORM或Django测试客户端等)
- 编写速度快
- 易于理解
- 发现任何集成问题都会提示
- 但是,并不总能得到好的设计
- 一般运行速度比隔离测试慢
-
隔离测试(使用mock等模拟)
- 涉及的工作量最大
- 可能难以阅读和理解
- 但是,这种测试最能引导你实现更好的设计
- 运行速度最快
解耦应用代码和 ORM 代码 力求隔离测试的后果之一是,我们不得不从视图和表单等处删除ORM代码,把它们放到辅助函数或者辅助方法中。 如果从解耦应用代码和ORM代码的角度看,这么做有好处,还能提高代码的可读性。当然,所有事情都一样,要结合实际情况判断是否值得付出额外精力去做。
由外而内的TDD
- 由外而内的 TDD
一种编写代码的方法,由测试驱动,从外层开始(表现层,GUI),然后逐步向内层移动,通过视图层或控制器层,最终达到模型层。 这种方法的理念是由实际需要使用的功能驱动代码的编写,而不是在底层猜测需求。 - 一厢情愿式编程
总是为还未实现的功能编写测试。 - 由外而内的缺点
这种技术鼓励我们关注用户立即就能看到的功能,但不会自动提醒我们为不是那么明显的功能编写关键测试, 例如安全相关的功能。需要记得编写这些测试。
持续集成
持续集成(Continuous Integration)
-
CI 服务器:Jenkins
-
尽早为自己的项目搭建CI服务器
一旦运行功能测试所花的时间超过几秒钟,应该将这个任务交给CI服务器,确保所有测试都能在某处运行。 -
测试失败时截图和转储 HTML 如果能够看到测试失败是网页是什么样,对调试更加便利。截图和转储 HTML 有助于调试 CI 服务器中的失败,而且对本地运行的测试也很有用
-
时刻准备调整超时 CI 服务器的运行速度可能没有本机快,尤其是同时运行多个测试、负载较高时。要时刻准备调整超时,设置它为较大值,尽量降低随机失败的概率
-
想办法把 CI 和过渡服务器连接起来
使用 LiveServerTestCase 的测试在开发环境中不会遇到什么问题,但若想得到十足的保障,就要在真正的服务器中运行测试。 想办法让 CI 服务器把代码部署到过渡服务器中,然后在过渡服务器中运行功能测试。这么做还有个附带好处:测试自动化部署脚本是否可用。
页面模式
减少功能测试中重复代码的方式,叫做“页面对象” 页面模型背后的思想是: 把网站中某个页面的所有信息都集中放在一个地方,如果以后想要修改这个页面,比如简单的调整 HTML 布局,功能测试只需改动一个地方,不用到处修改多个功能测试
- 可预见的变化
通常难以预测需求变化,但是根据现有需求预见将来的需求变化并不是不可能 - 不可预见的变化
但是可预见的变化并不一定会发生,有时甚至永远不会发生,还有的会因为某种原因转化为
使用常识,同时需要明白事情是会发生变化的,因此需要注意现有任务的优先级。
夹具(fixture): 为测试准备的一系列的对象状态。
重构
精髓: 小步修改,每次修改后就运行测试。
手法
临时整理:
- 以查询取代临时变量
- 检查传入参数是否是计算后获得
- 临时变量,且不再被修改。
- 函数声明
- 函数内部使用新提炼的函数
- 删除参数
- 修改函数名称
- 以子类取代类型码
- 引入子类,弃用类型代码
- 工厂函数取代构造函数‘’
- 以多态取代条件表达式
整理完成:
- 拆分循环: 分离出累加过程
- 移动语句: 将累加变量的声明与累加过程集中到一起
- 提炼函数:提炼出计算总数的函数
- 检查提炼到新函数后,哪些变量会被修改(在函数中直接返回,也可以在函数中初始化),哪些变量不会被修改(以参数方式传递)
- 函数是否能进一步提升表达能力
- 修改变量名,使其简洁
- 函数参数重命名
- 内联变量(inline variables):完全移除中间变量
为原函数添加足够的结构,以便能更好的理解,看清它的逻辑结构。 复杂的代码块分解为更小的单元,与好的命名一样重要
实现复用:
- 拆分阶段
- 搬移函数
- 以管道取代循环
重构过程的性能问题: 大多数情况下可以忽略它。如果重构引入了性能损耗,先完成重构,再做性能优化。
坏味道:
-
命名不准确(mysterious name)
- 函数声明(用于给函数改名)
- 变量改名
- 字段改名
-
重复代码(duplicated code)
- 提炼函数(提炼重复的代码)
- 移动语句(将相似的部分放在一起一边提炼)
- 函数上移
- 提炼函数(提炼重复的代码)
-
过长函数(long function)
- 提炼函数
- 以查询取代临时变量(消除临时元素)
- 引入参数对象
- 保持对象完整
- 以命令取代函数
- 分解条件表达式
- 以多态取代条件表达式
- 拆分循环
-
过长参数列表(long parameter list)
- 以查询取代参数
- 保持对象完整
- 引入参数对象
- 移除标记参数
- 函数组合成类(将共同的参数变成类的字段)
-
全局数据(Global data)
- 封装变量(用一个函数包装起来)
-
可变数据(mutable data)
- 封装变量(确保数据更新操作都通过很少几个函数来进行)
- 拆分变量(拆分为各自不同用途的变量,从而避免危险的更新操作)
- 移动语句 + 提炼函数(把逻辑从处理更新操作的代码中搬移出来)
- 查询函数和修改函数分离(针对 API,确保调用这不会调到有副作用的代码,)
- 移除设值函数
- 以查询取代派生变量
- 函数组成类
- 函数组成变换
- 将引用对象改为值对象
-
分散式变化(divergent change)
- 拆分阶段
- 搬移函数(将处理逻辑与数据分开)
- 提炼函数 + 搬移函数(将函数内部混合的处理逻辑分开)
- 提炼类
-
散弹式修改(shotgun surgery) *
移除局部变量的好处就是做提炼时会简单得多,因为需要操心的局部作用域变少了。
代码的实际运行路径?
可选择的编程方式:
-
将函数的返回值命名为 “result”
-
mock
- 使用驭件测试外部依赖,达到隔离外部副作用
- 使用驭件同时可以减少重复
url -> middle -> auth -> view -> model